Literature Review
A crucial aspect of the project is having an understanding of Braille. In our limited research we gathered that a typical textbook written in Braille has simple bumps corresponding to each alphanumeric and punctuation characters as shown in the images below. More information about it can be found at the American Foundation for the Blind website. The reader proceeds to move two of his fingers along a straight line trying to feel the bumps and decipher the text. Also, unlike English text, Braille is known to skip alphabets in certain words to shorten them as described by the American Foundation for the visually impaired. For example, the word ‘like’ is represented by the corresponding Braille characters of ‘lk’. However, our focus for the project will be to efficiently map each English alphanumeric character to the corresponding Braille cell with minimal error.
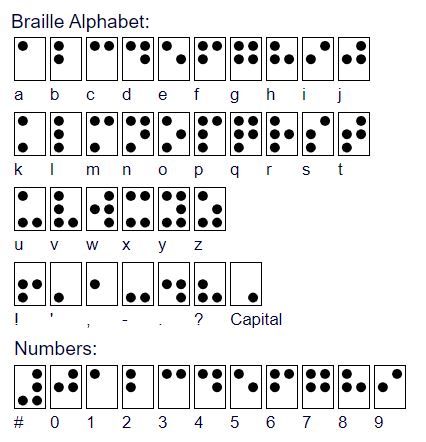

Image Processing
The first step of the project is setting up a pi camera that is compatible with the Raspberry Pi and capturing an image. The libraries used to set up the pi camera were PiCamera and OpenCV. Both of which are open source libraries available for python. The following snippet of code was used to set up the camera, and capturing an image after previewing it on screen and saving it the folder before deleting previous images.
import cv2 from picamera import PiCamera import os camera = PiCamera() #initialise an object of class picamera if os.path.isfile("/home/pi/Project/image.jpg"): os.remove("/home/pi/Project/image.jpg") print("FILE REMOVED") camera.start_preview() #use this object to start camera time.sleep(60) #delay camera.capture('image.jpg') #capture image and save as file image.jpg camera.stop_preview()
Once we had the camera working we then proceeded to build a wooden frame for the camera to rest and take pictures of a predetermined size. The camera is set at a height of approximately one feet above the base where a sample text page of letter size will be placed.


Once we had the image working we then proceeded to process the image. This is done by first converting it into greyscale and further using adaptive Gaussian filtering to remove noise and get a high contrast image necessary for processing through Optical Character Recognition (OCR). However, we just didn't stumble into this image processing. We took reference from a previous course project "Number Plate Recognition System" who have clearly documented all the steps we had tried and failed before finalising on Gaussian filtering.
# RGB to Greyscale img = cv2.medianBlur(img,5) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) noise_removal = cv2.bilateralFilter(gray,9,75,75) th3 = cv2.adaptiveThreshold(noise_removal,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\ cv2.THRESH_BINARY,11,2)
The processed image then looked something like below.

The next step is to convert the image into text using OCR. Pytesseract is an open source library available for python which does the job in minimal lines of code. The callback function “pytesseract.image_to_string(th3,lang='eng')” converts the processed image to text. This text is then further passed through a function which converts the characters to an index that references to a table mapping between the alphanumeric characters to a six bit array corresponding to active and passive state of the six dots in a typical Braille cell.
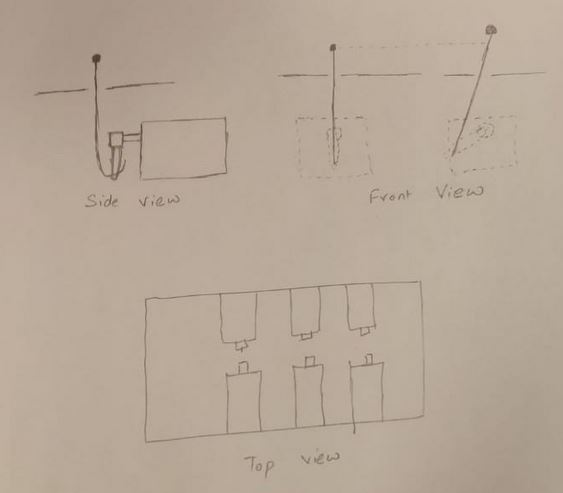
Actuators
The final output of the program is designed to be felt by a finger. And so, we designed a box fitted with 6 micro servo motors that move between the angles 0 to 45 degrees. The servo motors take a PWM output at a frequency of 50 Hz and change the angle of rotation with the change in Duty cycle from the range 12.5% to 62.5% for a 0 to 180 degree rotation. This circular motion is converted into a linear motion by hooking a straight 19 gauge wire to the tip of the motor horn and passing it through a hole on the roof of the box. The following image more clearly shows the set up of the motor mechanism. The wire is set to move freely at the joint of the servo such that the circular motion of the horn forces the wire to move in the only single degree of freedom allowed, which is upwards. This mechanism therefore, forms the bumps and flats necessary to be felt by the finger when deciphering the text.