Results
We have successfully developed the product as described in the design steps under sufficient light conditions and were able to test it for printed texts for various fonts and sizes ranging from 14 to 78. The fonts we have tested are Times New Roman, Calibri and Arial. However, it can be noted that any and all fonts possible in the pytesseract library can be processed and translated conveniently by our setup.
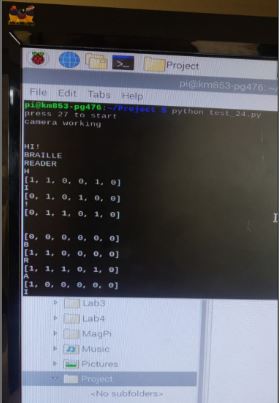
The flow of the system works such that, at the start it waits until the button connected to GPIO 27 is pressed which then triggers the camera to click a picture and start processing into a string. The entire output is set up into two modes; ‘fast’ and ‘slow’ mode. Slow mode is the default setup where the user can press a button (GPIO 23) to output one alphabet at a time. Along with it the ‘previous’ button (GPIO 22) repeats the output of the previous alphabet. The fourth button (GPIO 17) is used to toggle between the modes. When set in the ‘fast’ mode, the string is outputted one alphabet at a time without human intervention. Finishing the string brings the system back to the initial state. Pressing GPIO 27 button anytime during the above process quits the system and brings it to a stop state clearing the camera, PWM and GPIO setup. Every step of the process is also printed on the screen for convenience.


Conclusions
This project was the perfect culmination of the course ECE 5725 and the understanding of Raspberry Pi. Having set ourselves weekly targets and a final goal, we were successful to a positive extent at each step and delivered the product as expected. Working on image processing and OCR for the first time was mentally challenging in the beginning but however, the simplicity of Python and Raspberry Pi has made the task convenient to handle. All of which was possible with a major support from the professor and the TA’s whose mere presence in the lab itself motivated us to finish our work in time.
Future Work
For future work, there could be multiple points to focus. One, we could develop a better image processing algorithm wherein we detect the angle of the text in the image and skew it accordingly before processing through OCR. This could be a huge step ahead considering how the text in print media is never just plain text but coupled with other images and varying sizes and formats. Two, we could work on making the actuator system smaller. A typical Braille cell almost the size of a peanut. However, due to lack of expertise in 3D printing and/or mechanical systems, we designed a simple system which is a little oversized. Given the time, however, we wish to bring down the size of the actuator system. To finish it off, we would suggest making the system entirely compatible to the visually impaired. That is, replacing the steps printed on screen to a voice actuator or other actuators that the reader can recognize.