import RPi.GPIO as GPIO
import sys
import os
import numpy as np
import time
import pygame
from pygame.locals import* # for event MOUSE variables
from collections import deque
import math
import io
import picamera
from picamera import PiCamera
import cv2
from scipy.interpolate import UnivariateSpline
from simple_image_commands import *
import requests
os.putenv('SDL_VIDEODRIVER', 'fbcon')
os.putenv('SDL_FBDEV', '/dev/fb1')
os.putenv('SDL_MOUSEDRV', 'TSLIB') # Track Mouse clicks on piTFT
os.putenv('SDL_MOUSEDEV', '/dev/input/touchscreen')
####### INITIALIZATION ####################################
GPIO.setmode(GPIO.BCM)
# piTFT buttons
GPIO.setup(17, GPIO.IN, pull_up_down=GPIO.PUD_UP)
GPIO.setup(22, GPIO.IN, pull_up_down=GPIO.PUD_UP)
GPIO.setup(23, GPIO.IN, pull_up_down=GPIO.PUD_UP)
GPIO.setup(27, GPIO.IN, pull_up_down=GPIO.PUD_UP)
pygame.init()
pygame.mouse.set_visible(False)
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
menu_font = pygame.font.SysFont("caveat", 30)
screen = pygame.display.set_mode((0, 0), pygame.FULLSCREEN)
screen.fill(BLACK)
#####################Class Definition#####################
class Wheesh:
def __init__(self):
self.camera = PiCamera()
# we can make this the same as ScreenWidth/Height if u want, or have the image take up a different size
self.camera.resolution = (320, 240)
self.camera.rotation = 270
self.menu_font = pygame.font.SysFont("caveat", 30)
self.screen = pygame.display.set_mode((0, 0), pygame.FULLSCREEN)
self.screen.fill(BLACK)
self.stream = io.BytesIO
# state system
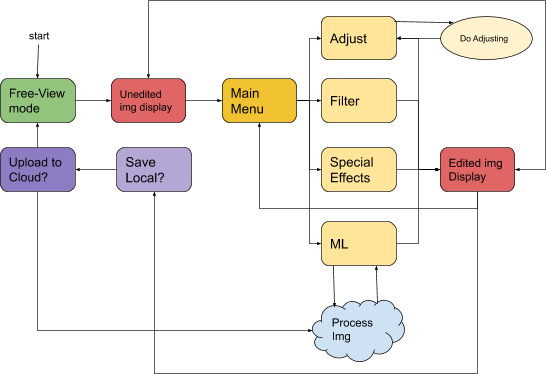
self._mainState = 0
# screen dimensions x 3 channels
self.rgb = bytearray(320 * 240 * 3)
self.current_image = []
self.edited_image = self.current_image
self.n = 0
self.curr_filename = "" # original filename
self.filename = "" # edited filename
self.tag = "" # prefix of filenames without file extension
self.timeout = 200 # timeout for ML prediction downloading
self.start_time = str(int(time.time())) + "_"
# 0:free view, 1:captured picture display (show orignal), 2: edited image
# 3:menu
# adjustment parameters
self.contrast = 1 # contrast --> multiplication
self.brightness = 0 # brightness --> addition
def inc(self):
self.n += 1
def CurrMode(self):
return self._mainState
def EnterState0(self):
self._mainState = 0
def EnterState1(self):
self._mainState = 1
def EnterState2(self):
self._mainState = 2
def EnterState3(self):
self._mainState = 3
####### IMAGE PROCESSING ####################################
def make_request(self, im, kind):
if kind == "mask":
resp = requests.get("http://ec2-34-205-78-136.compute-1.amazonaws.com:5000/mask/" + self.tag, timeout=150)
elif kind == "emotion":
resp = requests.get("http://ec2-34-205-78-136.compute-1.amazonaws.com:5000/emotion/" + self.tag, timeout=25)
else:
print "not a valid req type"
resp = ":("
return resp
def capture(self, rgb, stop=False, n=0):
stream = io.BytesIO()
self.camera.capture(stream, resize=(320, 240),
use_video_port=True, format='rgb')
stream.seek(0)
stream.readinto(self.rgb)
if stop:
self.camera.capture("img_"+self.start_time+ str(self.n)+".jpg")
self.curr_filename = "img_"+self.start_time+ str(self.n)+".jpg"
self.filename = "img_"+self.start_time+ str(self.n)+"_edited.jpg"
self.tag = "img_"+self.start_time+ str(self.n)
self.inc()
stream.close()
# decode = cv2.imdecode(np.asarray(rgb, np.uint8), cv2.IMREAD_COLOR)
pgi = pygame.image.frombuffer(rgb, (320, 240), 'RGB')
pgi_surf = pygame.surfarray.array3d(pgi)
self.current_image = cv2.cvtColor(
pgi_surf.transpose([1, 0, 2]), cv2.COLOR_RGB2BGR)
self.edited_image = self.current_image
test_upload(self.curr_filename, "upload_folder/"+self.curr_filename)
def pygamify(self, image):
# Convert cvimage into a pygame image
if len(np.shape(image)) == 3:
image2 = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
else:
image2 = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)
return pygame.image.frombuffer(image2.tostring(), image2.shape[1::-1], "RGB")
# Filter menu tasks: Taken from building instagram-like filters in python
def sepia(self, image):
print "sepia"
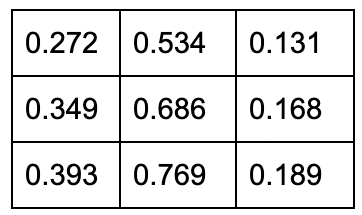
kernel = np.array([[0.272, 0.534, 0.131],
[0.349, 0.686, 0.168],
[0.393, 0.769, 0.189]])
self.edited_image = cv2.filter2D(image, -1, kernel)
def spreadLookupTable(self, x, y):
spline = UnivariateSpline(x, y)
return spline(range(256))
def warm_image(self, image):
print "warm"
increaseLookupTable = self.spreadLookupTable(
[0, 64, 128, 256], [0, 80, 160, 256])
decreaseLookupTable = self.spreadLookupTable(
[0, 64, 128, 256], [0, 50, 100, 256])
red_channel, green_channel, blue_channel = cv2.split(image)
red_channel = cv2.LUT(red_channel, increaseLookupTable).astype(np.uint8)
blue_channel = cv2.LUT(blue_channel, decreaseLookupTable).astype(np.uint8)
self.edited_image = cv2.merge((red_channel, green_channel, blue_channel))
def cold_image(self, image):
print "cold"
increaseLookupTable = self.spreadLookupTable(
[0, 64, 128, 256], [0, 80, 160, 256])
decreaseLookupTable = self.spreadLookupTable(
[0, 64, 128, 256], [0, 50, 100, 256])
red_channel, green_channel, blue_channel = cv2.split(image)
red_channel = cv2.LUT(red_channel, decreaseLookupTable).astype(np.uint8)
blue_channel = cv2.LUT(blue_channel, increaseLookupTable).astype(np.uint8)
self.edited_image = cv2.merge((red_channel, green_channel, blue_channel))
def gray(self, image):
print "gray"
self.edited_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# "Other" menu tasks
def restore(self):
print "revert changes"
self.edited_image = self.current_image
def cluster(self, image):
print "clustering"
# single channel as float
Z = np.float32(image.reshape((-1,3)))
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8 # number of clusters
# perform clustering
ret, label, center = cv2.kmeans(Z, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# back to uint8
center = np.uint8(center)
result = center[label.flatten()].reshape((image.shape))
self.edited_image = result
def pixelate(self, image):
print "8bit"
# scale image down with linear interpolation, scale back up with nearest neighbors
size = image.shape[:2][::-1]
downsize = (320/4, 240/4)
scaled_down = cv2.resize(image, downsize, interpolation = cv2.INTER_LINEAR)
scaled_up = cv2.resize(scaled_down, size, interpolation = cv2.INTER_NEAREST)
self.edited_image = scaled_up
def edge(self, image):
print "edge"
# Canny edge detection w/ hysteresis thresholding. Double check that thresholds are good.
self.edited_image = cv2.Canny(image, 100, 200)
# Adjust menu tasks
def adjust_contrast(self, mode):
print "contrast"
if mode == 0: # increase
self.contrast = 1.1
else:
self.contrast = 0.9
self.edited_image = cv2.convertScaleAbs(self.edited_image, alpha=self.contrast)
def adjust_brightness(self, mode):
print "brighter lol"
if mode == 0: # increase
self.brightness = 5
else:
self.brightness = -5
self.edited_image = cv2.convertScaleAbs(self.edited_image, beta=self.brightness)
def adjust_blur(self, mode):
print "blur lol"
# guassian blur
# repeatedly apply a blurring or sharpening filter (3x3) to an image with filter2D
if mode == 0: # more blur
kernel = np.array([[1,1,1],[1,-9,1],[1,1,1]])*-1
self.edited_image = cv2.filter2D(self.edited_image, -1, kernel)
else:
self.edited_image = cv2.blur(self.edited_image, (3,3))
def adjust_saturation(self, mode):
print "saturation"
# images stored in bgr format
imghsv = cv2.cvtColor(self.edited_image, cv2.COLOR_BGR2HSV).astype("float32")
(h, s, v) = cv2.split(imghsv)
if mode == 0: # increase
s = np.add(s, 5)
else:
s = np.add(s, -5)
s = np.clip(s,0,255)
imghsv = cv2.merge([h,s,v])
imgbgr = cv2.cvtColor(imghsv.astype("uint8"), cv2.COLOR_HSV2BGR)
self.edited_image = imgbgr
####### SCREEN UPDATES ####################################
def blit_text(self, s, pos):
text = s
text_surface = self.menu_font.render(s, True, BLACK)
rect = text_surface.get_rect(center=pos)
self.screen.blit(text_surface, rect)
def blit_image(self, img, pos):
pgi = self.pygamify(img)
self.screen.blit(pgi, pos)
pygame.display.flip()
def blit_icon(self, img_path, pos):
print "unimplemented"
def blit_main_menu(self):
self.screen.fill(WHITE)
self.blit_text("effects", (80, 180))
self.blit_text("filter", (260, 60))
self.blit_text("ML", (260, 180))
self.blit_text("adjust", (80, 60))
pygame.display.update()
def blit_adjust_menu(self):
self.screen.fill(WHITE)
self.blit_text("blur", (260, 60))
self.blit_text("contrast", (80, 60))
self.blit_text("brightness", (80, 180))
self.blit_text("saturation", (260, 180))
pygame.display.update()
def blit_filter_menu(self):
self.screen.fill(WHITE)
self.blit_text("warm", (80, 180))
self.blit_text("sepia", (260, 60))
self.blit_text("cool", (260, 180))
self.blit_text("noir", (80, 60))
pygame.display.update()
def blit_effects_menu(self):
self.screen.fill(WHITE)
self.blit_text("pixelate", (80, 60))
self.blit_text("edge", (260, 60))
self.blit_text("restore", (260, 180))
self.blit_text("cluster", (80, 180))
pygame.display.update()
def blit_ml_menu(self):
self.screen.fill(WHITE)
self.blit_text("emotion recognition", (160, 60))
self.blit_text("object detection", (160, 180))
pygame.display.update()
def blit_save_menu(self):
self.screen.fill(WHITE)
self.blit_text("Save Edited Img?", (160, 20))
self.blit_text("YES", (160, 60))
self.blit_text("NO", (160, 180))
pygame.display.update()
def blit_upload_menu(self):
self.screen.fill(WHITE)
self.blit_text("Upload Edited Img?", (160, 20))
self.blit_text("YES", (160, 60))
self.blit_text("NO", (160, 180))
pygame.display.update()
def blit_adjust_bar(self):
pygame.draw.rect(screen, WHITE, (0,200, 320, 40))
self.blit_text("+", (30, 220))
self.blit_text("-", (280, 220))
self.blit_text("done", (140, 220))
pygame.display.update()
def blit_message(self, message):
# another form of blit text
self.screen.fill(WHITE)
self.blit_text(message, (160, 120))
pygame.display.update()
####### EVENT HANDLING ####################################
def get_quadrant(self):
for event in pygame.event.get():
if event.type == pygame.QUIT:
sys.exit()
elif(event.type is MOUSEBUTTONDOWN):
pos = pygame.mouse.get_pos()
elif(event.type is MOUSEBUTTONUP):
pos = pygame.mouse.get_pos()
x, y = pos
# quit button (before game)
if x > 180 and y > 120:
return 1
elif x > 180 and y < 120:
return 2
elif x < 180 and y > 120:
return 3
else:
return 4
return 0
# handle contrast bar press
def get_bar_press(self):
for event in pygame.event.get():
if event.type == pygame.QUIT:
sys.exit()
elif(event.type is MOUSEBUTTONDOWN):
pos = pygame.mouse.get_pos()
elif(event.type is MOUSEBUTTONUP):
pos = pygame.mouse.get_pos()
x, y = pos
# quit button (before game)
if x < 70 and y > 200 :
return 1
elif x > 250 and y > 200:
return 2
elif y > 200 and x in range(50,250):
return 3
return 0
def handle_filter_menu(self, image):
quad = self.get_quadrant()
if quad == 1:
self.warm_image(image)
return False
elif quad == 2:
self.sepia(image)
return False
elif quad == 3:
self.cold_image(image)
return False
elif quad == 4:
self.gray(image)
return False
return True
_
def handle_effects_menu(self, image):
quad = self.get_quadrant()
if quad == 4:
print "8bit"
self.pixelate(image)
return False
elif quad == 3:
print "kmeans cluster"
self.cluster(image)
return False
elif quad == 2:
print "edge"
self.edge(image)
return False
elif quad == 1:
print "restore to default.."
self.restore()
return False
return True
def handle_contrast_bar(self, adjust_method):
self.blit_adjust_bar()
option = self.get_bar_press()
if option == 1:
print "plus"
adjust_method(0)
self.blit_image(self.edited_image,(0,0))
self.blit_adjust_bar()
return False
elif option == 2:
print "minus"
adjust_method(1)
self.blit_image(self.edited_image,(0,0))
self.blit_adjust_bar()
return False
elif option == 3:
print "submit"
return True
return False
def handle_adjust_menu(self, image):
quad = self.get_quadrant()
if quad > 0:
self.blit_image(image,(0,0))
self.blit_adjust_bar()
if quad == 3:
done_adjusting = False
while not done_adjusting:
done_adjusting = self.handle_contrast_bar(self.adjust_brightness)
return False
elif quad == 2:
done_adjusting = False
while not done_adjusting:
done_adjusting = self.handle_contrast_bar(self.adjust_blur)
return False
elif quad == 4:
done_adjusting = False
while not done_adjusting:
done_adjusting = self.handle_contrast_bar(self.adjust_contrast)
return False
elif quad == 1:
done_adjusting = False
while not done_adjusting:
done_adjusting = self.handle_contrast_bar(self.adjust_saturation)
return False
return True
def handle_ml_menu(self, image):
quad = self.get_quadrant()
if quad == 2 or quad == 4:
# get emotion image by s3 download
self.blit_message("loading detection...")
try:
print self.tag
test_download(local_download_path = self.tag+"_emotion.jpg", s3_file_name = "test_folder/" + self.tag + "_emotion.jpg")
self.edited_image = cv2.imread(self.tag+"_emotion.jpg")
return False
except Exception as e:
# file doesn't exist yet
code = 404
current_time = time.time()
while code == 404 and time.time()-current_time < self.timeout:
curr_time = time.time()
try:
resp = self.make_request(self.tag, "emotion")
except Exception as e:
print e
code = resp.status_code
print resp
print time.time()-curr_time
print "get"
if code == 404:
self.blit_message("prediction failed :(")
time.sleep(1)
else:
test_download(local_download_path = self.tag+"_emotion.jpg", s3_file_name = "test_folder/" + self.tag + "_emotion.jpg")
self.edited_image = cv2.imread(self.tag+"_emotion.jpg")
return False
elif quad == 1 or quad == 3:
# get mask image
self.blit_message("loading detection...")
try:
test_download(local_download_path = self.tag+"_mask.jpg", s3_file_name = "test_folder/" + self.tag + "_mask.jpg")
self.edited_image = cv2.imread(self.tag+"_mask.jpg")
self.edited_image = cv2.resize(self.edited_image, (320,240))
return False
except Exception as e:
# file doesn't exist yet
code = 404
current_time = time.time()
while code == 404 and time.time()-current_time < self.timeout:
curr_time = time.time()
resp = self.make_request(self.tag, "mask")
code = resp.status_code
print resp
print time.time()-curr_time
print "get"
if code == 404:
self.blit_message("prediction failed :(")
time.sleep(1)
else:
test_download(local_download_path = self.tag+"_mask.jpg", s3_file_name = "test_folder/" + self.tag + "_mask.jpg")
self.edited_image = cv2.imread(self.tag+"_mask.jpg")
self.edited_image = cv2.resize(self.edited_image, (320,240))
return False
return True
def handle_main_menu(self, image):
# case switch for each of the different quadrants
quad = self.get_quadrant()
if quad == 4:
# open adjustment menu
self.blit_adjust_menu()
adjusting = True
while adjusting:
adjusting = self.handle_adjust_menu(image)
return False
elif quad == 2:
# open filtering l2 menu
filtering = True
self.blit_filter_menu()
while filtering:
filtering = self.handle_filter_menu(image)
return False
elif quad == 3:
self.blit_effects_menu()
handling = True
while handling:
handling = self.handle_effects_menu(image)
return False
elif quad == 1:
self.blit_ml_menu()
handling = True
while handling:
handling = self.handle_ml_menu(image)
return False
return True
def handle_save_menu(self, image):
quad = self.get_quadrant()
if quad == 2 or quad == 4:
# save image
cv2.imwrite(self.filename, image)
return False
elif quad == 1 or quad == 3:
# do nothing
return False
return True
def handle_upload_menu(self, image):
quad = self.get_quadrant()
if quad == 2 or quad == 4:
# upload image
print quad
cv2.imwrite(self.filename, image)
test_upload(local_filename = self.filename, s3_file_name = "edited/" + self.filename)
return False
elif quad == 1 or quad == 3:
# do nothing
print quad
return False
return True
####### MAIN LOOP ####################################
w = Wheesh()
############ MAIN LOOP #########################
try:
while True:
# free view mode: menu isnt open and we aren't on a frame
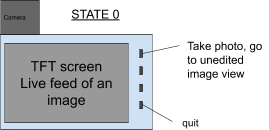
if w.CurrMode() == 0: # free viewing mode, have ability to take a picture
try:
w.capture(w.rgb)
img = pygame.image.frombuffer(w.rgb, (320, 240), 'RGB')
w.screen.blit(img, (0, 0))
except :
print "exceptioned"
GPIO.cleanup()
w.camera.close()
quit()
continue
# take a picture
if (not GPIO.input(17)):
w.capture(w.rgb, True, w.n)
print("picture taken")
w.EnterState1()
# captured picture display mode / (show orignal)
if w.CurrMode() == 1:
w.blit_image(w.current_image, (0,0)) #either update display right here, or move the blit into the "enter" functions
if ( not GPIO.input(23) ):
print "displaying edited image"
w.EnterState2()
# only open menu when frozen
if ( not GPIO.input(22) ):
print "opening main menu..."
w.EnterState3()
if (not GPIO.input(17)):
# todo: open save menu
w.blit_save_menu()
time.sleep(1)
save_menu_open = True
# process save menu actions:
while save_menu_open:
save_menu_open = w.handle_save_menu(w.edited_image)
w.blit_upload_menu()
upload_menu_open = True
time.sleep(1)
# process upload menu actions:
while upload_menu_open:
upload_menu_open = w.handle_upload_menu(w.edited_image)
w.EnterState0()
# edited picture display mode (show edited)
if w.CurrMode() == 2:
w.blit_image(w.edited_image, (0,0))
if ( not GPIO.input(23) ):
print "displaying original image"
w.EnterState1()
# only open menu when frozen: can open menu from edited image
if ( not GPIO.input(22) ):
print "opening main menu..."
w.EnterState3()
if (not GPIO.input(17)):
# todo: open save menu
w.blit_save_menu()
time.sleep(1)
save_menu_open = True
# process save menu actions:
while save_menu_open:
save_menu_open = w.handle_save_menu(w.edited_image)
w.blit_upload_menu()
upload_menu_open = True
time.sleep(1)
# process upload menu actions:
while upload_menu_open:
upload_menu_open = w.handle_upload_menu(w.edited_image)
w.EnterState0()
# effects main menu mode
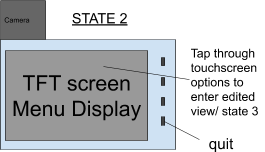
if w.CurrMode() == 3:
# if main menu is not open
w.blit_main_menu()
main_menu_open = True
# process menu actions:
while main_menu_open:
main_menu_open = w.handle_main_menu(w.edited_image)
print "done with menu. showing edited image now"
w.EnterState2()
# quit at any time
if ( not GPIO.input(27) ):
print "Thanks for trying out the SmartCam :)"
GPIO.cleanup()
w.camera.close()
quit()
pygame.display.update()
except KeyboardInterrupt:
GPIO.cleanup()
w.camera.close()
quit()









































 Laasya
Laasya
 Anirudh
Anirudh