BeeCam V2
Zoe Du and Yixuan Wang
jd963 and yw277
5/22/2020
Objective
This project is the second version of BeeCam project in Spring 2020. We aim to build a box-like device to observe bees’ behaviors. Our goal is to identify each bee with numerical tags and record images of bees while they are in the tunnel. Two Raspberry pi are also synchronized to provide the same time stamp for images.
Introduction
This project is about to implement a bee-observation device for studying behaviors of honeybees at different periods. We firstly label each bee with unique numerical tag and then automate the process of tag detection to identify them. The system is mainly made of two raspberry pis and two cameras. One camera targeting at the side of the tunnel will idle at speed of 35 fps and signal the camera on the top to start capture images. The top camera will take images while the bees are in the tunnel and process these images to extract tags while it idles. After the number of tags are predicted by our convolutional neural network model, we store the information to the disk. Such information allows us to have more insights into honeybees and their behaviors.
Design
This final design evolved through the idea of first version and have drastic changes due to the replacement of AprilTag with numerical tags. AprilTag is a visual fiducial system popular in detecting predefined tags with fast detector and it also has powerful functions which output the position and orientation of tags in the images. However, with the substitution of numerical tags, we have to train our own machine learning models for tag detection and also reconstruct software and hardware to optimize the capturing speed and detecting speed.
Another major difference from the first version is that we took off the break beam sensors and let the camera take the responsibility of detecting the entry/exit of bees by taking a threshold value on binarized images. As a result, the side camera is enough to idle for the entry of bees and the other one could work on tag detection in the meanwhile. In this case, User Datagram Protocol (UDP)
communication is set up between two Pis. Network time protocol(NTP) is implemented to synchronize the clocks on two raspberry pis such that images captured by two cameras share the standardized time stamps.
Software
General
Software side is mainly consisted of the code of Pi camera, Image processing, UDP communication and NTP protocol. Multithreading is implemented for the camera to capture images at a high frame rate. 20 threads for the capturing are initiated and rotating in the pool. These 20 threads will directly capture images to the IObuffer instead of saving to the disk to both optimize the time and space. After images are saved to the iobuffer, some threads for tag detection are initialized and appended to the queue. When the camera is in the rest and starts to idle, these tag-detection threads will be popped up from the queue and the thread starts to work.
Pi Camera
There are two cameras. One targeting at the center of the tunnel from the top and the other from the side. The side one (sender) is used as a sensor to detect the entry of bees and then signal the top camera (receiver) to start working. In this way, while the cameras capture images, only the sender needs to perform preprocessing on the images and determine if captured images contain any bee. The receiver can just take images at full speed as soon as it receives the signal from the side camera. In this case, sender can reach 30 fps while it needs to both capture images and detect bees. The receiver can reach 60 fps since it only needs to capture images to the IObuffer without any calculation.
The camera is capable of capturing a sequence of images extremely rapidly by utilizing its video-capture capabilities with a JPEG encoder (via the use_video_port parameter), however, the disadvantages are the smaller image capture area and captures appear to be grainer since capture from still port uses a more intensive denoise algorithm.
We used the video port to capture image continuously with Camera.capture_sequence(streams(), use_video_port=True).
Compared with capture() and capture_continous() function proviced in PiCamera libraray, capture_sequence() is by far the fastest method (because it does not re-initialize an encoder prior to each capture). The function reqires an input like filename or IObuffer where it can save images to. We passed a fucntion stream() which will yield the processor.stream, an IObuffer associated with each thread.
Here in the streams function, we have external callback button controlling the vriable done. If not done, by acquring the lock, our threads waiting in the queue will be popped up one by one. The stream vairable of each thread is initialized with IObuffer so when we yield process.stream, camera will directly capture images to the buffer associated with each trhead. In the meanwhile, a unique id count is passed to the instance. If the pool is empty, it will poll for a short period of time.
def streams():
global done
global cnt
global test
global data
while not done:
with lock:
if pool: #a pool of thread instances
cnt+=1
processor = pool.pop()
else:
processor = None
if processor:
processor.cnt=cnt
yield processor.stream
processor.event.set()
else:
# When the pool is starved, wait a while for it to refill
time.sleep(0.1)
ImageProcessor is inherited from thread.Thread() class and it has extra fields of stream,event,terminated,start(). Stream is associated with the position of image in ioBuffer. An event manages a flag that can be set to true with the set() method and reset to false with the clear() method. The wait() method blocks until the flag is true. The flag is initially false.
class ImageProcessor(threading.Thread):
def __init__(self):
super(ImageProcessor, self).__init__()
self.stream = io.BytesIO()
self.event = threading.Event()
self.terminated = False
self.start()
self.cnt=0
def run(self):
# This method runs in a separate thread
global cnt
global test
while not self.terminated:
if self.event.wait(1):
try:
self.stream.seek(0)
# Read the image and do some processing on it for each camera
finally:
# Reset the stream and event
self.stream.seek(0)
self.stream.truncate()
self.event.clear()
# Return ourselves to the pool
with lock:
pool.append(self)
I. The side camera (Sender)
The sender camera is always on and constantly taking images at a speed of 30 fps. It is responsible for detecting the entry of bees. It will perform preprocessing on the images save in the buffer and apply a threshold on the sum of binary images after fileter. The sender has image processing code inserted in the run() method of ImageProcessor() class
# the global data shared with UDP thread,
if set as 1, the sender will send 1 to the receiver through UDP
global data
a=Image.open(self.stream) #open the image in ioBuffer
origin=a.crop((7,130,640,480))
#convert to grayscale images
f=origin.convert('LA')
#apply filter on the image to convert it to bianry image
threshold = 30
im = f.point(lambda p: p > threshold and 255)
pxl_count=sum(sum(np.uint16(f)/255))
if pxl_count[0] <52500:
data=1
II. The top camera (Receiver)
The receiver will not start capturing images until the Sender tells it to start. The images captured at a fast speed will be pushed to a FIFO queue and while Receiver idles, it will take item from the queue and process any pending threads of tag detection.
#global
q=Queue(maxsize=0)
#In run() of ImageProcessor()
image=Image.open(self.stream).crop((7,130,640,480))
q.put((image,self.cnt))
threads.append(Tag_detect(q,self.cnt))
#In run() of calss Tag_detect()
image=q.get()
User Datagram Protocol (UDP) thread
User Datagram Protocol (UDP) is used for the communication between two rasberry pis via ethernet cable. UDP makes use of Internet Protocol of the TCP/IP suit. A client program sends a message packet to a destination server where the server also receives the massage from UDP. Because there won't be much traffic between two pis so we can save time by using UDP instead of TCP. In the sender side, we only send when we detect a bee. The receiver has a thread constantly polling to receive from the sender. The sender will decide if it will send 1 or 0 to the receiver after it processs the images in the buffer
#receiver
def udp_thread():
sock=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
sock.bind((UDP_IP,UDP_PORT))
global data #shared vairable with the image capture thread. 1 is set if there's bee
global terminate_udp
while not terminate_udp:
dat, addr= sock.recvfrom(1024) # buffer size is 1024 bytes
d=dat.decode()
data=int(d[0])
Network Time Protocol (NTP)
Network time protocol(NTP) is an Internet protocol used to synchronize the clocks of computers to some time reference. The side camera (Sender) with a RTC clock is set a server which synchronize its time with the internet whenver it's connected with wifi. The Receiver is set as NTP client. it frequently sends requests to the NTP server and inquire the time. First, we need to get ntp package using apt-get install ntp and then edit the file /etc/ntp.conf to configure the pi to be the server or the client. The server will broadcast to client's IP address and client will sends requests to server's IP address
Image Preprocessing
I. Tag Extraction
For each image, we need to find and extract the tag on the bee, recognize the number on the bee and be able to tell the system if there is no bee in the image. To perform these image processing in python3, opencv, tensorflow and keras are installed and used.
The function tag_extraction() accepts an image input, which is the picture taken by the top camera and returns a 78*78 image which contains the tag of the bee in the image, or an empty image if there is no bee found. Details of the tag extraction algorithm is below:
- Rotate the image 90 degrees clockwise
- Convert image from BGR to HSV color-space
- Apply a threshold to the image from (30,40,20) to (90,255,255)
- Mask the image where only the pixel value is within given in the range
- Convert the result of thresholding image to grayscale
- Apply cv2.HoughCircle Detection to the grayscale image;
- Among all detected circles in the image, select the one with the highest confidence
- Get the tag image from the input image of the by taking the square with (a,b) as center and 2*radius as height and weight from the input image
- If the radius is smaller than 39, append zero pixels on the border; if the radius is greater than 39, crop the image to 78*78
- In case the tag is on the border and the height and weight does not match (for instance, 76*78 instead of 78*78), append zeros to the shorter direction
- If there is no circle detected, return a 78*78 grayscale image with all pixels equal to zero
- If the pixel is partially blocked (i.e. part of the tag is outside the picture), return a 78*78 grayscale image with all pixels equal to zero
def tag_extraction(image):
# read image and apply green color filter
img = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv, (30, 40, 20), (90, 255,255))
imask = mask>0
green = np.zeros_like(img, np.uint8)
green[imask] = img[imask]
gray = cv2.cvtColor(green, cv2.COLOR_BGR2GRAY)
# detect circles, param2 is used to control the confidence of detected circles, the higher
# param2 is, the less likely the model predicts a false circle
detected_circles = cv2.HoughCircles(gray,
cv2.HOUGH_GRADIENT, 1, 20, param1 = 50,
param2 = 1, minRadius = 10, maxRadius = 50)
if detected_circles is not None:
# Convert the center coordinates (a,b) and radius to integers
detected_circles = np.uint16(np.around(detected_circles))
pt = detected_circles[0,0]
a, b, r = pt[0], pt[1], pt[2]
cv2.circle(green, (a, b), r, (255, 255, 255), 2)
# crop and extract tag
roi = img[b-r:b+r,a-r:a+r]
# return empty image if tag is on the edge
if roi.shape[0] == 0 or roi.shape[1] == 0:
tag = np.zeros((78,78))
tag = np.uint8(tag)
return tag
# make tag into a square if it is not
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
if gray_roi.shape[0] != gray_roi.shape[1]:
if gray_roi.shape[0] < gray_roi.shape[1]:
new_roi = np.zeros((gray_roi.shape[1],gray_roi.shape[1]))
new_roi[0:gray_roi.shape[0],0:gray_roi.shape[1]] = gray_roi
else:
new_roi = np.zeros((gray_roi.shape[0],gray_roi.shape[0]))
new_roi[0:gray_roi.shape[0],0:gray_roi.shape[1]] = gray_roi
gray_roi = new_roi
# crop to size 78*78
if gray_roi.shape[0] > 78:
gray_roi = gray_roi[r-39:r+39,r-39:r+39]
tag = gray_roi
elif roi.shape[0] < 78:
tag = np.zeros((78,78))
tag[39-r:39+r,39-r:39+r] = gray_roi
tag = np.uint8(tag)
else:
tag = gray_roi
return tag
# get the tag
tag = tag_extraction(image)

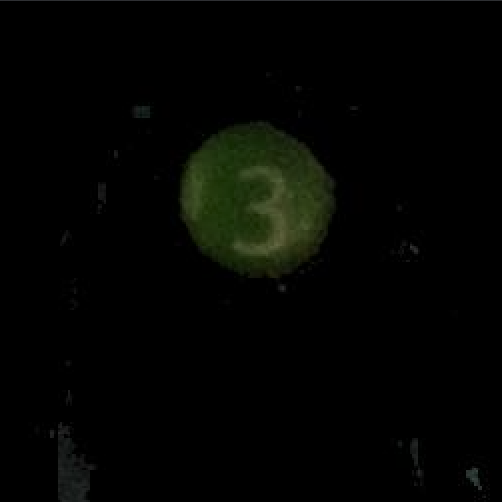
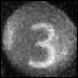
The figure above on the left shows the original image. The figure in the middle shows the filtered image and the figure on the right shows the extracted tag. The tag image extracted to this step is used as input to the machine learning model for tag number prediction.
II. Machine Learning and Tag Read
We used machine learning with a convolutional neural network to perform the number recognition on tag. In our project, there are eight possible tag numbers : 1-8 used in the model. We want the model to predict the tag number given the tag image extracted from the bee by the previous step. Because there exists pictures that only has partial blocked tags (on the border of the picture) or no tags at all as mentioned above, we want the model to have an additional prediction class “0” such that when the model determines that there is no bee in this image, it outputs a 0 as its prediction.
To implement the machine learning algorithm, we first collected a training dataset by taking approximately 1500 images for each bees with each tag number. We also took approximately 1500 images in which there are no bees in the images. Each of those images is processed and has its tag extracted. We also record the tag number corresponding to each image so that we have a training target dataset. 10% of the training data is randomly selected as the validation set. The training labels 0-8 are converted one-hot vectors of length 9. The training samples and training labels are then forwarded to the convolution neural network. The overall structure of the network is shown below. The "None" parameter represents the number of images input.
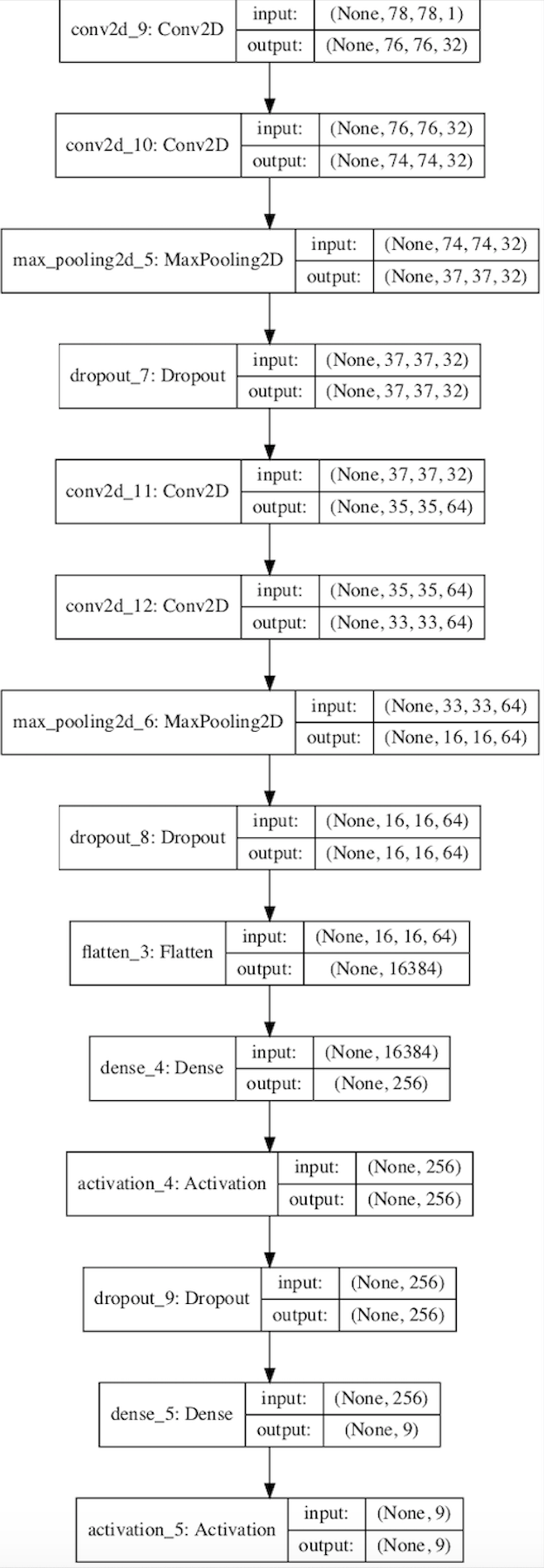
The model outputs a vector of length 9, representing the probability of the input image carrying each number (or no tag detected for label 0). We then select the label with the highest probability to use it as the prediction of tag number.
The loss function used in this model is categorical cross entropy. For optimizer, we used ADADELTA. We also included a callback method to regularize the learning rate such that once the validation loss stops decreasing for a consecutive of 4 epochs, it reduces the learning rate by 0.5 with minimum learning rate equals to 0.00001. The batch size is 64 and number of epochs is 30. The training process is done on another computer to accelerate the process although we can also train the model on Raspberry Pi.
After we trained the model, it is saved to a h5 file. When our program starts, it loads this h5 file. The function tag_read() accepts a tag image input, and then the model then predicts the image and outputs a prediction. We return this prediction to the program to tell if there is a tag captured in this image and the tag number if there is a tag.
#load model
model = load_model('tag_model.h5')
def tag_read(images):
# reshape the input image to match training shape
image = image.reshape(1,78,78,1)
image = image.astype('float32')
image /= 255
# prediction
prediction = model.predict(image,batch_size=1,verbose=1)
pred_class = np.argmax(prediction,axis = 1)
pred_class = pred_class
return pred_class
#put image to the function and get predicted tag
pred = tag_read(sample)
Hardware
The system is mainly consisted of two rasberry pi and two cameras. Each pi has a RTC clock to preserve synchronized time and a USB flash drive to store images for later processing. The box is a laser-cut wood board and there's a transparent tunnel made of laser-cut acrylic. The LEDs inside the tunnel are covered with thin tissue paper for the purpose of diffusion. Ethernet cable is used for UDP and NTP protocols. A push button connected to GPIO 13 is used as callback function to exist the program.



Testing
I. Issues and Solutions
We first tried to use Optical Character Recognition (OCR) for recognizing the number on the tag. To successfully use OCR, we explored a lot of different combinations of image processing functions including: RGB thresholding, grayscale thresholding, increasing image contrast with histogram-equalization, dilation, erosion and opening. Because the lighting in environment might differ significantly depending on where the bee is located in the tunnel, we did not apply additional image processing steps like thresholding and filtering, as it is hard to set up an universal or adaptive filter that works for every image because the conditions and visibility of tags on each image can be very difficult. In addition, OCR cannot solve the problem of bright light spots caused by reflection of the LED lights inside the tunnel because the light spots might have very large sizes which make the extraction of tag numbers very difficult. Even when we get a relatively clean image, the OCR also fails the detection with a high possibility. In our best image preprocessing model, the accuracy was about 66%. The OCR also runs very slow compared with machine learning prediction. Because of the low accuracy and low speed, we finally decided to switch to machine learning and the machine learning performed very well.
A second issue was that when we used the machine learning model in multithreading, tensorflow always returned a source loading error. We later found out the problem was that the tensorflow graphs and sessions are not thread level safe. Each time we call the thread, tensorflow creates a default session that does not contain the previously loaded model’s information. To solve this problem, we set two global variables for the tensorflow session and graph at the beginning of the program. Each time we call the machine learning prediction thread, we set the session and graph to the global graph and session, and this problem was then solved.
In our early testings, we did not include the detection of empty images (i.e. when there is no tag detected) into our training dataset, which led to our model predicting random numbers when the model reads an input of an empty image. To fix this problem, we added the empty images into the training dataset and test performace was very successful.
II. verification
To confirm our program work as expected, we take incremental approach and test as well as we add more features. Firstly, we tested our NTP after we configure the one rasberry pis to be the server and one to be the client.

By using dead bee with numberical tag attached to it, we can easily test our programs

Next step is test our Sender is working properly and send the data as we expected. From the image below we can clearly see that the camera is idling at the speed of 30 fps and 1 is sent through UDP to the Receiver. The following number is the date when the number is sent
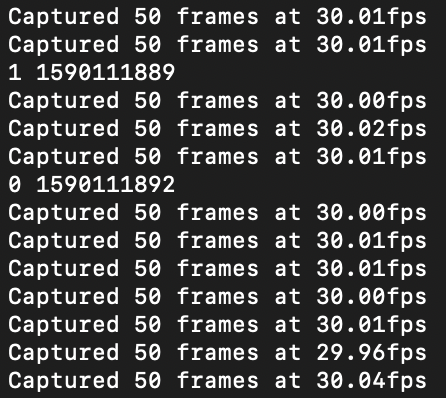
Our receiver is confirmed to work by testing if it take picutres when it receives a 1 and start tag detection when it doesn't receive 1. In the following image, it's clear that the program starts to do the tag detection when it stops receiving 1.

Results
Everything performs as planned and there’s still room for improvement. We successfully set up and optimize the system in a way that both cameras work at a fast rate which is necessary to capture images of bees. We meet the goals of tag detection where we implemented a machine learning model that has pretty high accuracy. We take advantage of saving images in the buffer and perform different image processing at several stages for optimization. For further results, our device will be deployed on real farms and collect information about real bees.
We trained the model for 30 epochs and the training accuracy curve is shown below.
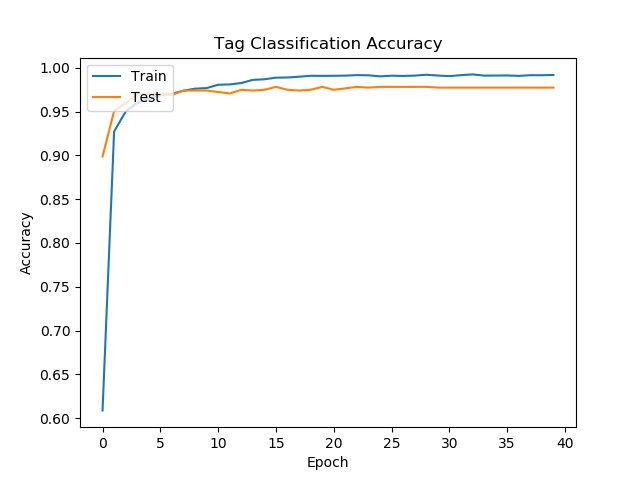
As the figure shows, the neural network has a 97% validation accuracy in predicting the tag numbers (or 0 if there is no bee in the image). We also used a dead bee on a stick and we moved it back and forth inside the tunnel to mimic the motion of bees. The model was able to make very fast predictions about whether there is a bee in the tunnel, and what the tag number is if there is a bee with tag detected. Therefore our algorithm performed as planned and met the goal of successfully detecting and predicting the tag numbers as outlined in the description.
Future Work
As professor indicated in the demo, we might encounter the problem that the buffer will overflow if the bees stay in the tunnel for a long time. In this case, our top camera will continuously capture images without taking a rest. One possible solution is to set a limit of time or perform background subtraction on the images after a period of time.
In our machine learning model, we can detect 8 different tag numbers and whether there is a tag detection. I think future work could be focusing on designing an efficient model that could detect a massive number of different tags. It will be interesting and challenging to design a machine learning model that could perform classification on hundreds of differnt tags. In addition, some additional properties can be added to the classification labels. For instance, we can have two different labels for tags for tags carrying the same number but have different direction as a measure to determine the direction of the bee at the time when the image taken. Another possibility is to have tags in different colors and allow the model to train and predict RGB images. This will allow us to use multi-color tags if one color is not enough for a large number of bees.
Conclusion
In general, our demo went as we expected and all the functions we implemented were working. We achieved most of our goals stated in the proposal like bee tag detection and high-speed capturing; We are able to successfully detect whether there is a bee in the tunnel, extract the tag, and read the tag with fast speed and high accuracy. In comparison with Optical Character Recognition, the machine learning method gives much faster and accurate predictions, and it is less likely to be affected by the dynamic environmental factors.
However, we fail to build image processing algorithm for pollen detection on the side camera. It took us a while to denoise the images since capturing with video port over 40 fps will give us grainer images and smaller image capture area. To reduce the reflection problem of tags, we also spent a large chunk of time to adjust the lighting inside the device without the help of soldering station and digital multimeter. The minor problems can also be addressed later with possible solutions.
We obtained experience of using multithreading in the embedded system and see how memory, read/write time and CPU influence our projects. We also explored the machine learning model to facilitate identifying bee tag numbers. It’s a good practice of integrating all the knowledge form different areas and apply to real life problem
Code Appendix and reference
Work Distribution
Zoe Du: in charge of the system design, impelemented multithreading image captue, image processing of detecting bees, NTP and UDP communication.
Yixuan Wang: in charge of bee tag extraction and detection. Perform CNN machine learning and image processing.
Material List
| Name | Unit Price |
| 2 Pi Camera V2s | $29.95 |
| 1 Raspberry Pi B+ | $34.99 |
| 1 Raspberry Pi 4 | $45 |
| Clear Acrylic | $2.5 |
| Ethernet cable | $2 |
Contact
Zoe Du (jd963@cornell.edu) Yixuan Wang (yz277@cornell.edu)