Multi-Raspberry Pi Compute Server
ECE 5725 - Design with Embedded Operating Systems
Project Team: Swapnil Barot (spb228), Muhammad Moughal (mm2774), Jaemok Yoon (jy392)
December 15, 2021
Project Objective
The Multi-Raspberry Pi Compute Server is a project that is designed to showcase the computational advantages of a Raspberry Pi cluster computer. The cluster consists of four (4) total Raspberry Pis, out of which, three (3) are configured as "workers" and one (1) is configured as a "manager". Edge detection using sobel filters with and without multithreading with OpenMP is utilized to test the cluster’s performance. An end user application for image processing using this cluster is developed to assist programmers who can benefit from the computational advantages of the high number of cores with respect to the low cost of a Raspberry Pi.
Demonstration Video
Introduction
“The faster the better,” an expression used in everyday life, is highly applicable to computing applications. There is always a need for processing that can significantly improve computing power and execution time. Most processors today are defined as multicore systems, meaning they are equipped with multiple cores to provide greater performance via multiple-threading. This project utilized several Raspberry Pi 4 Model B, each containing a quad-core 64-bit ARM-Cortex A72 processor that is suitable for multi-threading.
The Multi-Raspberry Pi Compute Server is designed to exploit the Raspberry Pi's parallelism features and execute computations across four (4) Raspberry Pis (16 total cores) utilizing OpenMP and NFS (Networked FIle System). The cluster of the four (4) Raspberry Pis consists of one (1) manager and three (3) "workers". Edge detection using a sobel filter is the target application utilized for this project. Sobel filtering is a technique utilized for edge detection that functions by calculating the gradient of image intensity at each pixel within an image.
The use of the distributed file system achieves a speed up of around 1.5-2x of a basic sequential node when processing 500 video frames, depending on the addition of multithreading or no multithreading. An in depth case by case analysis is given after our evaluations in the results section.
Design
Hardware Configuration
The cluster consists of four (4) Raspberry Pis, one (1) ethernet switch, CAT 6 network cabling. As seen in Figure 1 below, the Raspberry Pis are connected to the ethernet switch via Cat 6 cabling. "Manager" Raspberry Pi is connected to wifi and executes tasking to the workers via the ethernet switch. This setup enables the Raspberry Pis to communicate with each other via the ethernet switch while the “manager” is connected to the wifi to access network capabilities.

Figure 1 - Hardware Configuration
Cluster Configuration
Utilizing a distributed cluster where a "manager" sends tasks to the "workers'' requires initial cluster configuration. First, the ethernet switch was set up to create a communication platform between the manager and the workers. Then, the manager was configured. “Dispy '' was installed to allow for the users to write code on the manager and run it across the workers, using the following command: $ sudo pip3 install dipsy. Nmap was installed to discover the IP addresses of the Raspberry Pi workers, using the following command: $ sudo apt-get install nmap. Then, the client software that contains source code and bash control script for rebooting and shutting down the cluster were downloaded by using the following command: $ git clone https://github.com/raspberrypilearning/octapi-setup.git. To complete the setup for the manager, the command $ mv /home/pi/octapi-setup/client/* /home/pi , was implemented to move all the files from the client folder into the /home/pi folder.
Next, the manager was set up on the network. First, one of the workers was connected to the ethernet switch. Then the following command was used to collect the IP address of the client Raspberry Pi: $hostname -I. The following command was used to find the IP address of the worker: $ nmap -sP 192.168.1.*.
MPI Implementation
MPICH is a well-known and standardized implementation of MPI that is capable of exchanging messages between multiple computers running a parallel program. MPI was installed using the following command: $ tar -xzf mpich3-3.2.tar.gz. After, MPI was configured by performing $ ./configure. Once MPI was downloaded and verified locally, it was implemented across the entire LAN cluster. First the hosts file was set up to capture the IP address of all the machines on the LAN. Then a new user was created in the cluster using the command: $ sudo adduser mpiuser. Next, the SSH protocol was installed and set up for communication and data sharing via NFS. NFS is then set up to enable the manager to share a directory with the workers. Then, example programs were tested to confirm the functionality of the MPI implementation. However, we ran into some obscure errors with MPI that we had not seen and could not consult resources because there weren’t many to begin with. We decided to focus on an alternative, which is the NFS distributed file system. We saw that for cluster implementations, the focus is often on OpenMP and MPI for computations, and considered if a distributed file storage system would hold up here as well. Our configuration for MPI helped us here as we had already set up the storage along with the connections across the nodes. So it was a smooth transition into a different, but equally interesting research question.
NFS Implementation
Approaching this implementation, our question was largely about whether this would yield an improvement or not. We know that MPI itself has its own overheads – for example, many nodes will do their computations and then wait for the rest of the nodes to get to a certain shared point before moving forward. Additionally, we found that system calls with MPI to send and receive data can also take overhead. However with NFS we theorized that our nodes can make their own progress and compute the filters independently. Still, since NFS is a file system, we had to figure out how nodes would distribute the task. Additionally, if each node was writing its own image and was sending its copy to be stored into this single system, then it's possible that the system would lock access to each node, save files sequentially, and thus completely limit our improvement to zero! Hence we had 2 overarching questions guiding us into this implementation:
(1) Would using NFS create a speed up at all whether we use sequential or multithreaded computations?
(2) If not, or if so, what could be the cause of this speed-up or non-speed-up?
To implement our distributed computation system, we had four directories for four nodes. Each directory served as the input/output directory of each node. We decided to distribute the task file by file to minimize inter-node communication. If we’re given 100 files, then we distribute 25 files to each node’s directory, and each node does its computation on the images in their directory. We make extensive use of bash scripts and Python to distribute files and invoke the correct commands for each of the workers and as well as the manager itself.
Edge Detection Using Sobel Filter
The algorithm we tested our performance with was the sobel filter. The sobel filter is one of the earliest algorithms developed for edge detection – which today is extensively used for computer vision applications of detecting and tracking objects. Nowadays, machine learning is used for this task, but sobel filter still has a place as its one of the most well known image processing algorithms. This algorithm starts with two 3x3 matrices, one for the x direction and one for the y direction gradients called the kernels. We apply the gradient to each pixel to find the change in y and change in x. Adding it all together, we get the change in pixels from both directions for which higher values can show it as brighter – thus showing the parts of the image where sharp changes happen, i.e., the edges. Our program is implemented in C, we make use of the standard library to load and save files, and we make use of arrays to hold matrices and computations on the image. We had some trouble with the low level details for this filter, so we consulted open source resources and guidelines for both versions which we refer to in the references.
OpenMP Implementation
Our OpenMP implementation uses four threads on four cores to split the image in quarters by row. In sobel.c, using the load image function, we can make use of ‘fopen’ in C to load the file and double check that it's usable by our program. We also have a save image function to write back the updated image to the older image. This replaces the image which we felt was sufficient for our workflow. The sobel filtering function is the meat of this file. It is like the regular implementation, except we make use of ‘#pragma omp’ before our for loops to define the variables that will be kept private and as well as variables that will be shared. For instance, to make sure that our four threads don’t iterate over the same pixels, we use private (i, j) and apply our dot products individually across each thread. In order to “share” a piece of data across the node for an image wide variable, we use share(data). Otherwise most of the code was – to our surprise – very similar to the single threaded code, except now we split the loops with the ‘#pragma omp’ directive. The last function, main() takes care of I/O and handling function calls. Next, sobel.h defines the functions such as saving and loading image, and defines the weights we use as the sobel operator as ‘const int …’ to indicate they stay constant.
OpenCV Implementation
To extend our project, we applied OpenCV for video streaming. We felt that our sobel filter implementation and setup made use of open source guidelines and resources and we wanted to extend our project by extending this with a new program altogether. With this program, a user can make use of this cluster’s computational power by loading in a video and filtering it autonomously.
Specifically, after this video is loaded into the cloud/Tasks/streams directory, we use a function called read_frames.py to load the video with OpenCV and read each frame of the video. After each read, an image file is distributed to a node directory by the modulus operator as so: file-id % 4, where 4 is the number of nodes we have. Each node then gets an even share of a quarter of the files, plus a remainder as necessary. Then the user can run either the sobel_omp (for multithreaded) or sobel_seq (for sequential) computation by invoking run_all.sh. This script runs SSH into each of the worker nodes and starts another script called run_1.sh which runs the sobel computation for all the images in the node’s directory, by using modulus on the file-ids again. Lastly, we use convert_frames.py and to_video.sh to convert the .pgm frames from the sobel filter function back to .jpg and create a video using ‘ffmpeg’. The user can then view the processed video in the ‘streams’ directory.
System Diagram
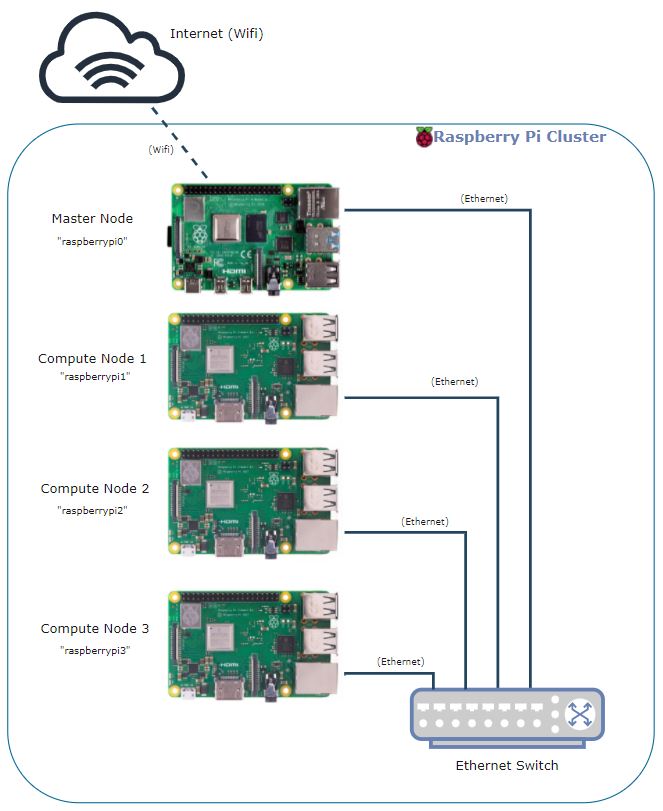
Figure 2- System Diagram
Testing
With the streaming set up done, we’ve created an application for a real world use case that a user may want to do, which is to leverage a cheap cluster to perform a computationally heavy task of image processing on a video. While this is currently restricted to sobel filters, our implementation is modular enough that just replacing a line or two in a script will adapt it to a different processing algorithm as long as it computes on each image individually.
However, we still wanted to ask our main research question of whether the distributed file storage we’re using would help with our implementation or not. We conducted testing by using the linux ‘time’ command to get the real, user, and sys time. We’re focused on the real and user time, where real represents the wall clock time elapsed between start and end of the program (like timing a run with a stopwatch) and user time represents the time the CPU cores spend doing the computation. Both are relevant metrics here, as real time takes into account the I/O operations which include reading/writing and accessing files. Unlike the real time, the user time only measures the CPU execution time for the code, which can be helpful to see if our code itself is computationally efficient or not.
We compare results from several experiments to compare speedups. For our main research question, the most important comparison was between the single node computation and the multi-node cluster computation that is based on NFS. We also have a sequential program and a multithreaded program. Our experiments are set up to use 512 bytes of image size (the ‘medium’ size) and we run for 100, 300, and 500 frames of a video.
Comparing Performance Between One Node and Four Node Cluster (Sequential):
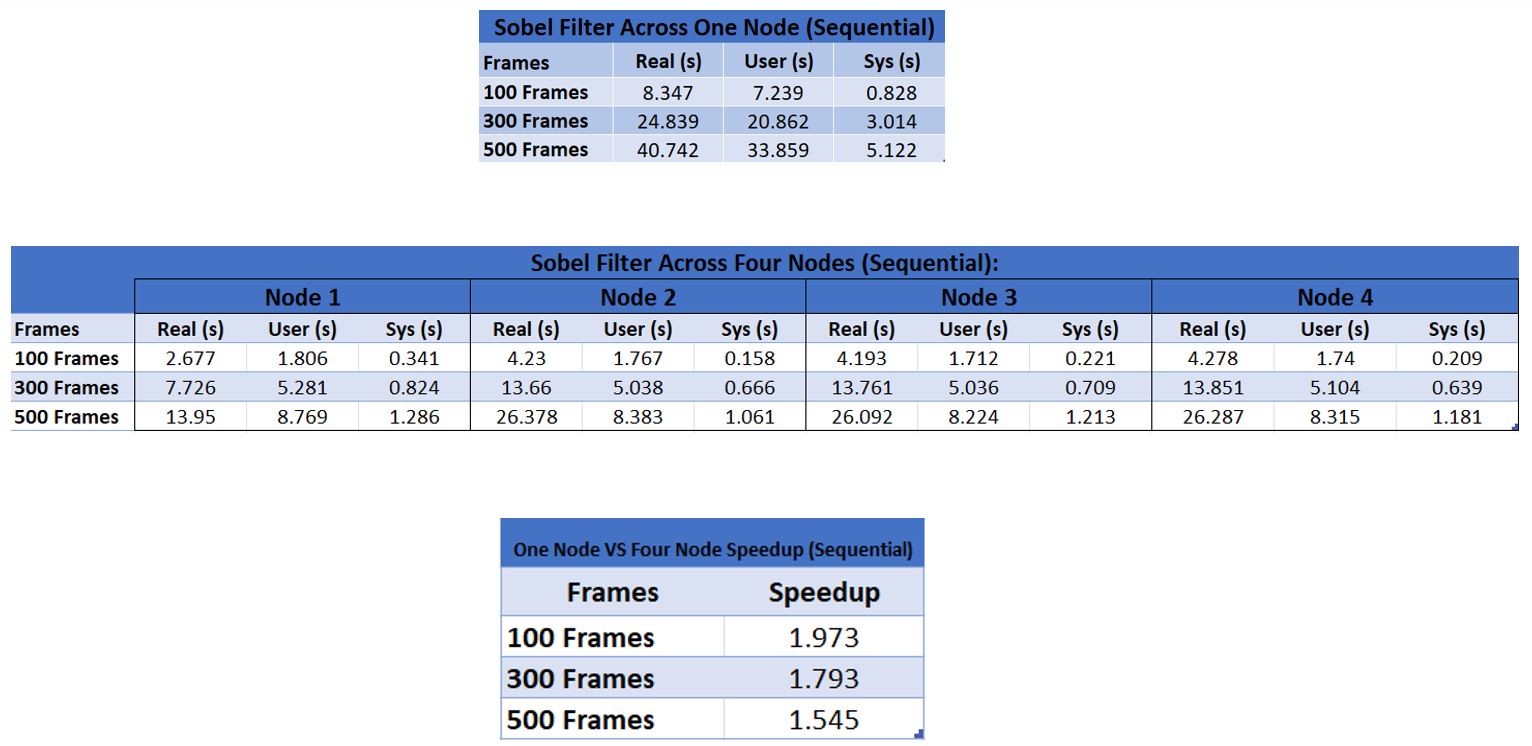
Figure 3
Comparing Performance Between One Node and Four Node Cluster (OpenMP):
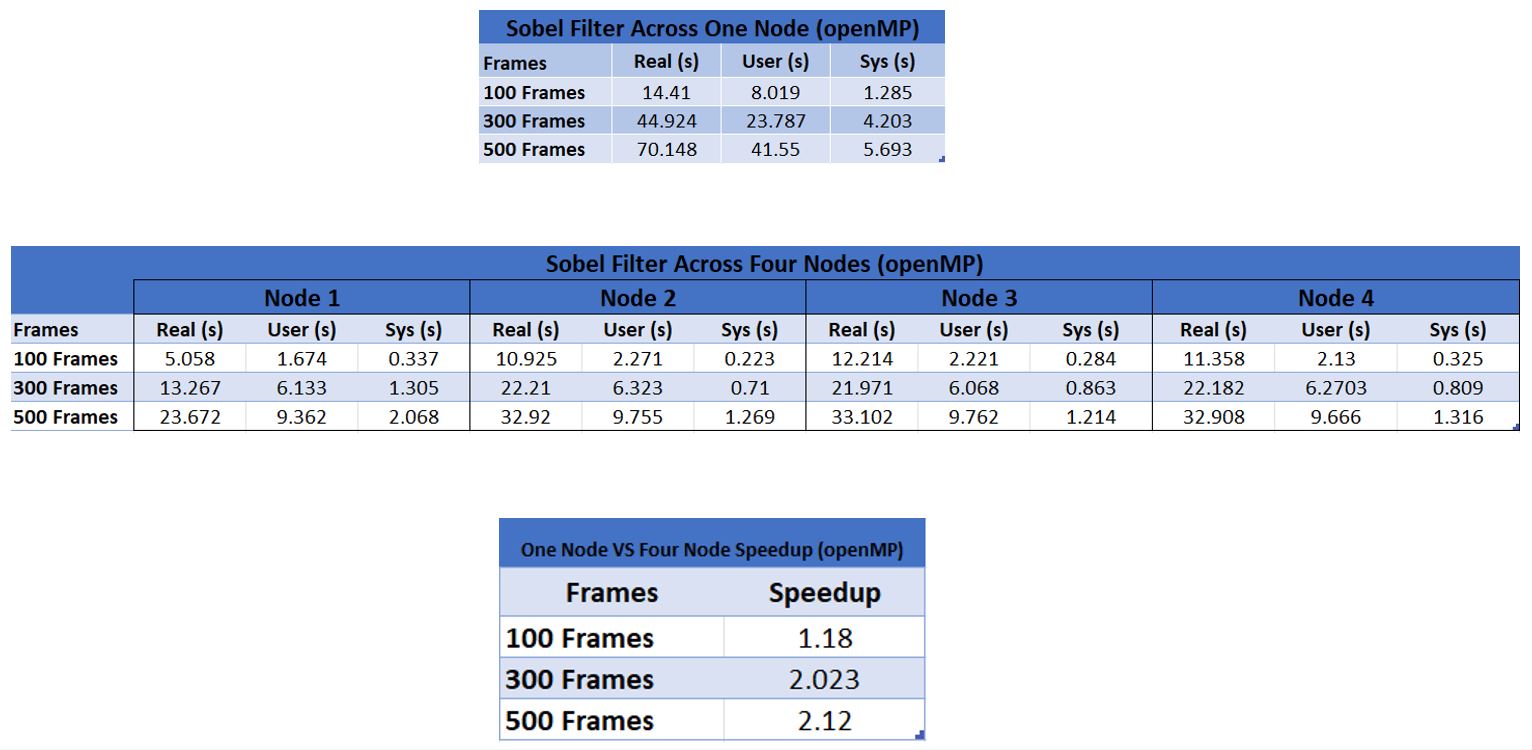
Figure 4
Comparing Speedup Between One Node (Sequential) and Four Node Cluster (OpenMP):
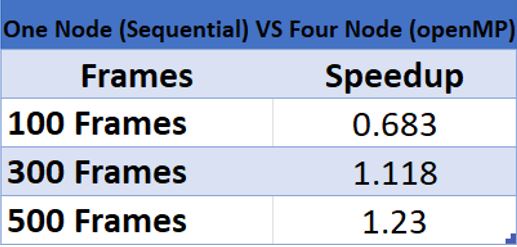
Figure 5
Result
First comparing the OpenMP vs sequential results, right away we can see that for low frames, the performance gain is small or even negative. However, as the frames increase, so does the performance gain of the OpenMP based implementations. This is likely because with low frames, the overhead of cores communicating with OpenMP is higher than the performance gain, so the program is slower than one would expect initially.
Comparing the results between one node and four nodes, both for sequential and OpenMP cases, we were pleased to see some performance gains between the single node vs. NFS based cluster. However, in our one node vs four node, sequential case, the gain actually decreases as the file number increases. Looking at the ‘real’ time which considers I/O, it was much higher than CPU time for the worker nodes which access the files through the network rather than locally like the manager node. We think that it is due to this I/O load that the gain decreases. It's possible that the gain continues decreasing, which would mean that the cluster with NFS actually isn’t useful performance wise! Comparing the one node vs. four node with OpenMP, we see that there is an increasing performance gain as frames increase – however it is possible that it is entirely due to OpenMP’s performance gains.
Challenges
There were two major challenges we encountered: one was the setup with the OctaPi implementation, and the other was the setup with the MPI implementation. It's possible that we missed something in the initial setup with the new Raspberry Pi 4s, but nonetheless it did not pose us a problem when we moved forward with the NFS implementation of the cluster. Overall, we still ended up using what worked from our configurations for the OctaPi and the MPI cluster. Specifically, we used the ethernet setup from the OctaPi and we used the file storage and SSH setup, among some other lower level ideas, from the MPI set up. Other than that, the sobel filter gave us trouble initially but we consulted open source resources and research papers to move forward. Since our project was mainly about performance evaluation and the addition of an end user application, we felt that consulting the resources for lower level graphics and C knowledge was sufficient.
Future Work
Considering our data and evaluations, it would be interesting to continue working this experiment with higher frames. We would like to see the trend on a much longer frame and time scale. Does the NFS based improvement really approach zero (or negative) if the frames and images are too high? If so, is there a way to counteract it? One way we could try would be to store the images for the worker nodes locally, have them process their images, and send them back to NFS. However, this may still pose I/O issues because it's just delegating the task of sending files later in the computation. Additionally, we only tried a medium, 512 bytes image size, we could try doubling this size to 1024 and higher and see what the trend of performance gain/reduction is as we keep the frames constant. Lastly, we could evaluate this system against a 16 core desktop in terms of raw compute power as well. Would this ~$100 setup hold against a much more expensive desktop computer? That remains to be seen! All in all, there are many different directions for further research to our project here.
Work Distribution

Muhammad Moughal
mm2774@cornell.edu
Developed and debugged software for openMP, cluster configuration, and openCV; Tested the overall system; Created the website.

Jaemok Yoon
jy392@cornell.edu
Developed and debugged software for MPI and NFS; Tested the overall system; Created the website.

Swapnil Barot
spb228@cornell.edu
Configured the hardware system; Tested the overall system; Assissted in debugging software; Created the website.
Appendix
Parts List
- Four (4) Raspberry Pis: Existing Inventory
- Four (4) Raspberry Pi Cases - $10.00/Each
- One (1) Ethernet Switch: $20.00
- Four (4) CAT 6 Network Cabling - $2.50/Each
Total: $70.00
References
Build an OctaPi, Raspberrypi.orgRaspberry Pi 4 Model B Datasheet, Raspberrypi.org
An Implementation of Sobel Edge Detection - Rhea
Sobel Edge Detector
Sobel Filter (OpenMP implementation) - Stack Overflow
GitHub - eduucaldas/parallel-sobel-filtering
Parallelized Sobel algorithm using OpenMP - Code Review Stack Exchange
Sobel Filter (OpenMP implementation for Knights Landing) - Intel Communities
Code Appendix
The code can be found on the linked Project Github Repository.