Emotion-Response Speaker
An intelligent speaker that plays music based on human facial expressions
A Project By Sheng Li (sl3292) and Xinran Li (xl792).
Demonstration Video
Introduction
We built an intelligent speaker on Raspberry Pi that is able to play different kinds of music base on the human’s facial expressions. In the project, we tried with different models to create bottleneck features and implemented deep learning algorithms for testing and training. The models and algorithms were manually tested for accuracy and time efficiency before we decided our final design. Human’s facial expression features are captured by a picamera, and the computer vision algorithms will process the features on the Raspberry and classify the features into seven different emotional expressions. The seven emotional expressions are divided into three classifications including positive, negative, and neutral emotions. The positive classification includes happy emotion, when the negative classification includes fear, sad, and angry emotions. And other expressions are put into neutral classification. A mini speaker is used to play music and is installed on the speaker frame of our Raspberry Pi. If the human facial expression is detected and classified as happiness, the speaker will play a random music selected from a list of cheerful music. While a negative expression is detected, the speaker will play a random music selected from a lost of relaxing music. The intelligent speaker is set in a pig sculpture assembled by a papercraft building kit. After we successfully implemented our facial expression detection system, our intelligent speaker can analyze real-time video footage in Python and play music based on the human’s facial expressions.

Project Objective:
- Implement the human facial expression detection algorithm.
- Implement the python script for picamera to analyze real-time video footage and extract facial features of a human from the footage.
- Assemble the Papercraft Building Kit and fit the Raspberry Pi and picamera into it.
- Test and optimize the intelligent music player.
Design and Testing
The design of the system can be classified into two major aspects: the facial expression analysis, and the music selection. To extract facial features of a person from a video stream and then determine the emotion status, we started with building a neural network model. We expected our model can predict the correct emotion in a real time level and yield a good accuracy, therefore, the performance of the model should follow two constraints: latency and accuracy. In order to make the model to deal with most real-life circumstances, we need a dataset that large enough to train the model.
Dataset Collection
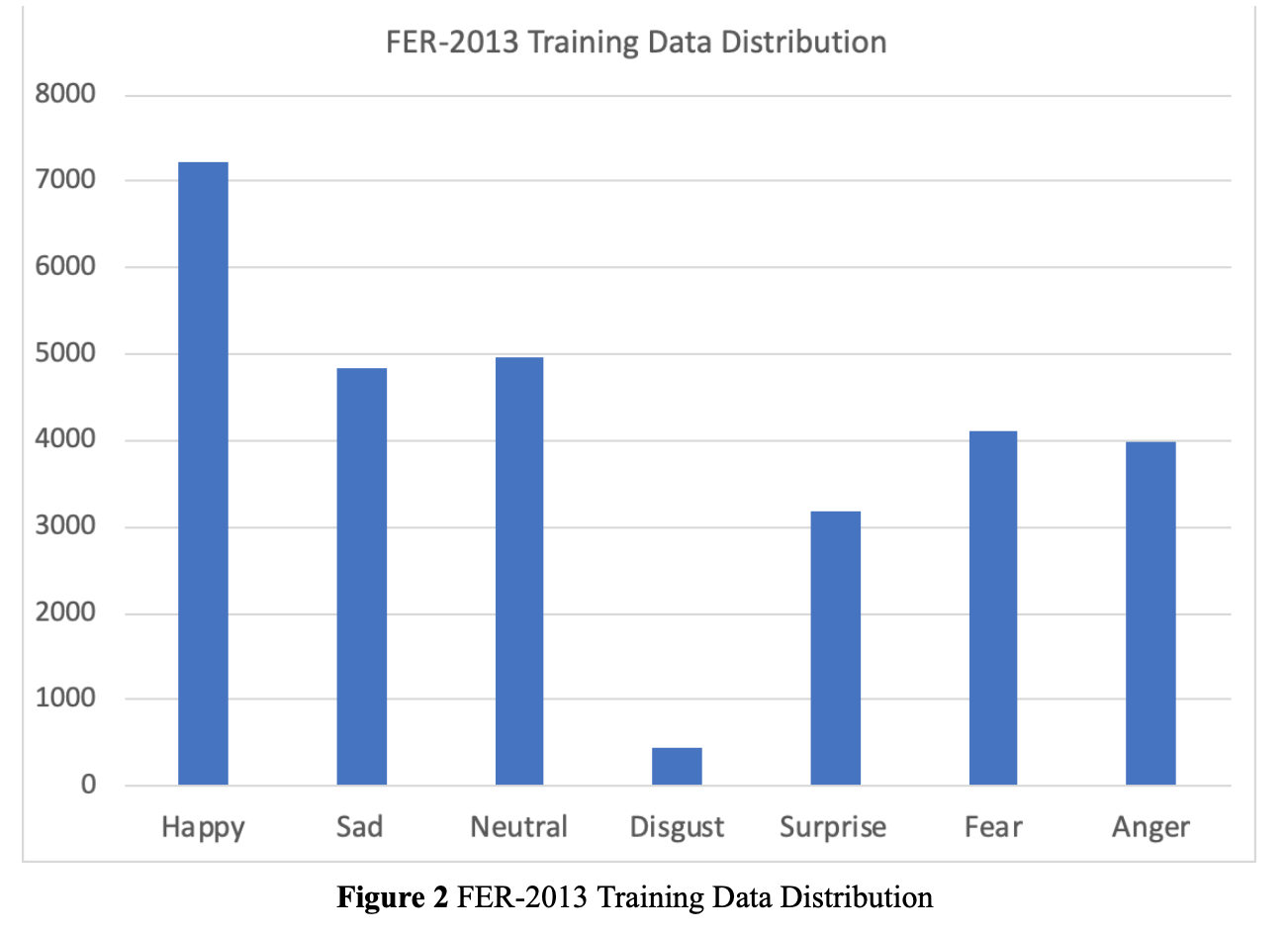
The dataset for training and testing the model was initially the Cohn-Kanade (CK and CK+) database and The Japanese Female Facial Expression (JAFFE) database. Both of the databases are popular for expression recognition, however, the number of images doesn’t match our expectation and the labeling metric of CK database requires certain time to classify the data. Happy, sad, surprise, anger, disgust, fear, and neutral are 7 general facial expressions. The CK dataset provides one more facial expression, which is contempt. Since the facial expression of contempt is similar to disgust, we removed this classification. Another problem was that the number of images for each expression is not equally distributed. Since we majorly focused on the happy and sad expressions for playing music and one solution we had was to categorize the prediction results into three major classes: happy, sad, and neutral. As we researched more about the dataset, we found the FER-2013 dataset. This dataset contains 35887 image examples with 48*48 resolution. The following figures show the data distribution of classified CK+JAFFE and FER-2013 data.

Transfer Learning
Our initial approach was to utilize transfer learning to achieve a higher accuracy in prediction. We used VGG-16 to create bottleneck features for the model. This decision was made based on the fact that building a convolutional neural network model from scratch is time inefficient due to its characteristic of computationally expensive operation and the self-built model may yield poor results. Our task is basically a classification task, weights from a previously well-trained task can help to initialize our network. Therefore, we expected transfer learning to increase the accuracy of our specific task by extracting feature maps from the popular pretrained image classifier. In this case, we used VGG16 model in Keras applications with ImageNet weights and no top of the network included. We replaced the top of the VGG16 model with our self-designed MLP that consists of five fully connected (dense) layers to produce the classification probability for the seven emotions.
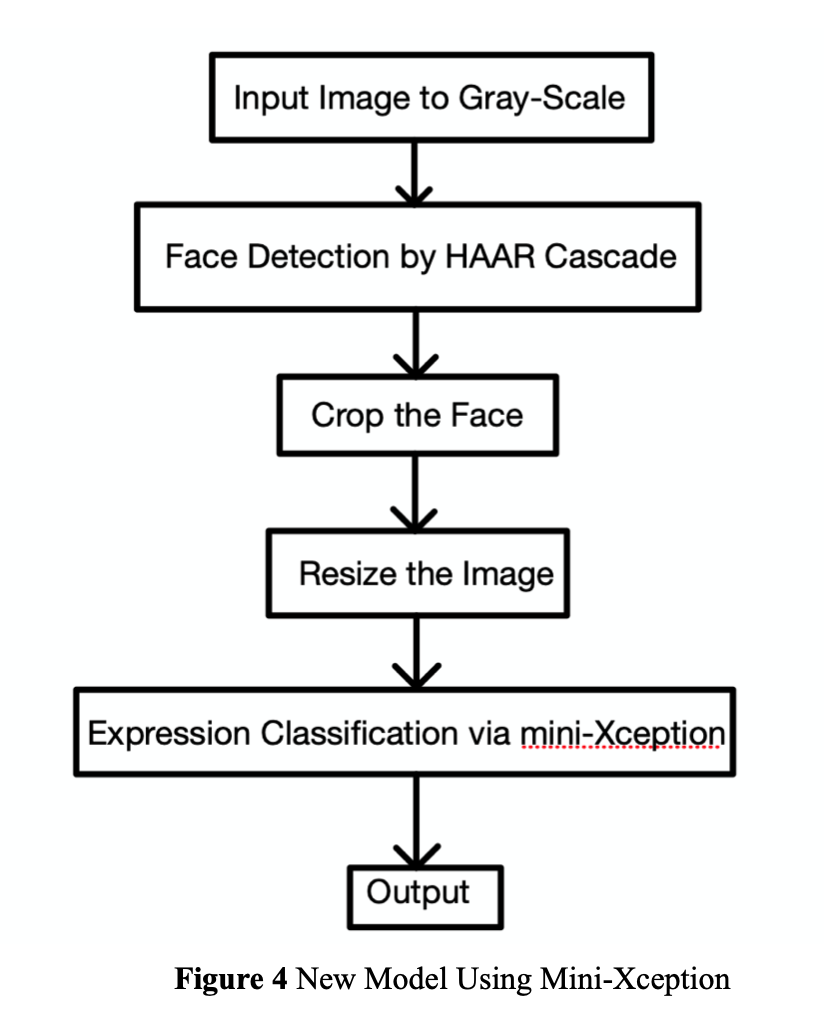
Before the images being processed by the model, the images need to be pre-processed. Considering the real-time cases, the system needs to know whether there is a face and the frame needs to be cropped to fit the format that the model can take. We used Haar-cascade to detect the face and the OpenCV provides xml file for this part. To detect the face and recognize the facial expression successfully, an image that contains a face needs to be converted to grayscale first since classification doesn’t depend on colors and 1-channel image requires less learnable parameters than 3-channel image; then, the face is cropped from the original image via Haar-cascade detector and resized to the defined size; the VGG-16 creates bottleneck features from the resized image and feeds the features to the top MLP classifier. The following diagram provides the details of the model we have tried. Due to the limitation of the Pi as a computation-powerful platform, we trained and tested the model on our local machines and saved the model into h5 file that can be loaded and used on the Pi.

We tried different sizes of the input image to exam how the size can affect the inference accuracy. 350 by 350, 224 by 224 and 48 by 48 were tried for our test purpose. We found that the larger the size, the higher the accuracy. However, the accuracy doesn’t vary significantly but the inference time can reduce in a significant way. By understanding the impact of input size on inference time, we were able to make our model more efficient. We finally decided to resize the cropped face image into 48 by 48 before feeding it to the model. The network has 26,388,103 trainable parameters, which is not a desirable model for an embedded device. MobileNetV2 was then introduced to replace VGG-16 for bottleneck feature extraction due to its lightweight architecture and powerful performance on embedded machines. However, the results were bad, more trainable parameters were added. By redesigning the top MLP module into a more compact form with 3 fully-connected layers, we successfully reduced the trainable parameters to 6,439,555, which is only 24% of the first model. We examined the model on the raspberry Pi 3 and it took 5 seconds to predict an image. It took 2 seconds to predict on the raspberry Pi 4. Although the model can achieve desired accuracy but it didn’t satisfy the latency requirement.
Mini-Xception
We noticed the bottleneck features increased the number of parameters. Since cropped face from every single frame was required to create features first, the time for overall inference became longer. Therefore, the transfer learning is a good approach for offline processing but may not be suitable for our real-time task on embedded device. The paper, Real-time Convolutional Neural Networks for Emotion and Gender Classification, published by Octavio Arriaga, Paul G. Plo ̈ger, and Matias Valdenegro helped us to improve the inference time. The mini-Xception they proposed is a lite emotion classifier inspired by popular Xception [1]. Based on our calculation, this network only has 56,951 learnable parameters for 48 by 48 input image. The model has been shrunk significantly. By utilizing this model, the time for feature extraction can be saved and a cropped face image can be fed to the model directly. The new model can predict a frame in a real-time level and requires only 0.037 seconds on raspberry Pi 3.
For playing music, we initially implemented with FIFO to make the emotion prediction program and music playing program run independently. Pygame provides another solution that it can play music in background and doesn’t block the the program. We used pygame instead and combined the two programs into one program to maintain the simplicity.
Results
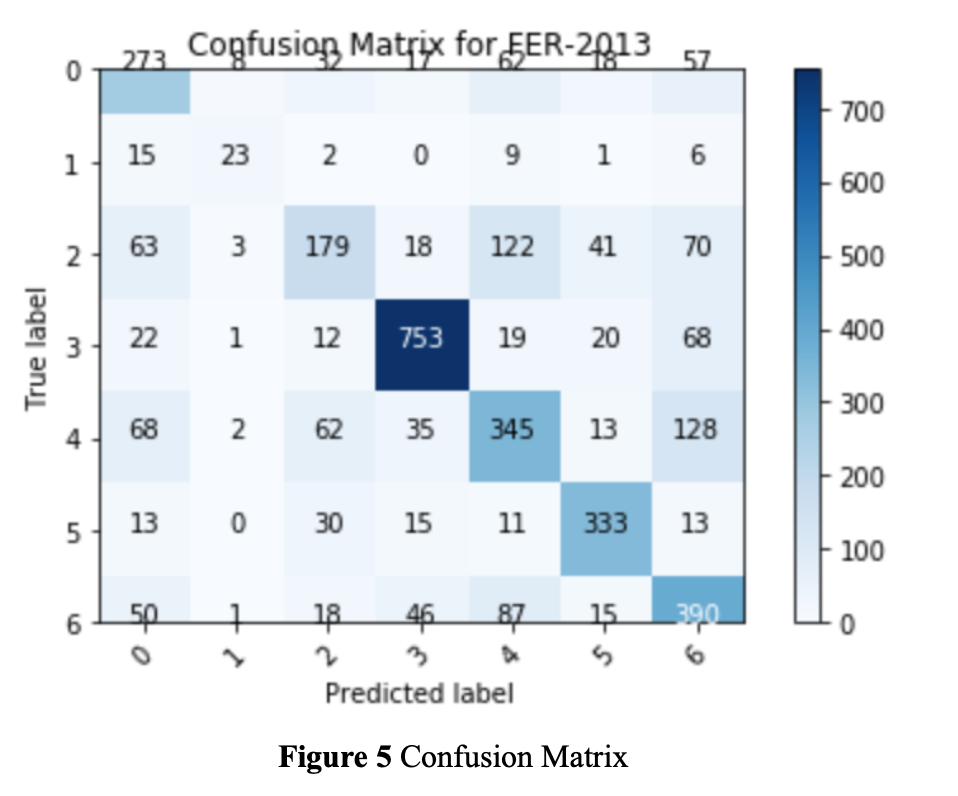
We started with a very large model with long inference time and finally ended up with a lite model on embedded device with real-time efficiency. The following figure shows the confusion matrix tested on the FER-2013 public test dataset where 0=Anger, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, and 6=Neutral. We achieved 64% on the public testing dataset and we believe this is a reasonable report since some images in FER-2013 dataset are mislabeled.
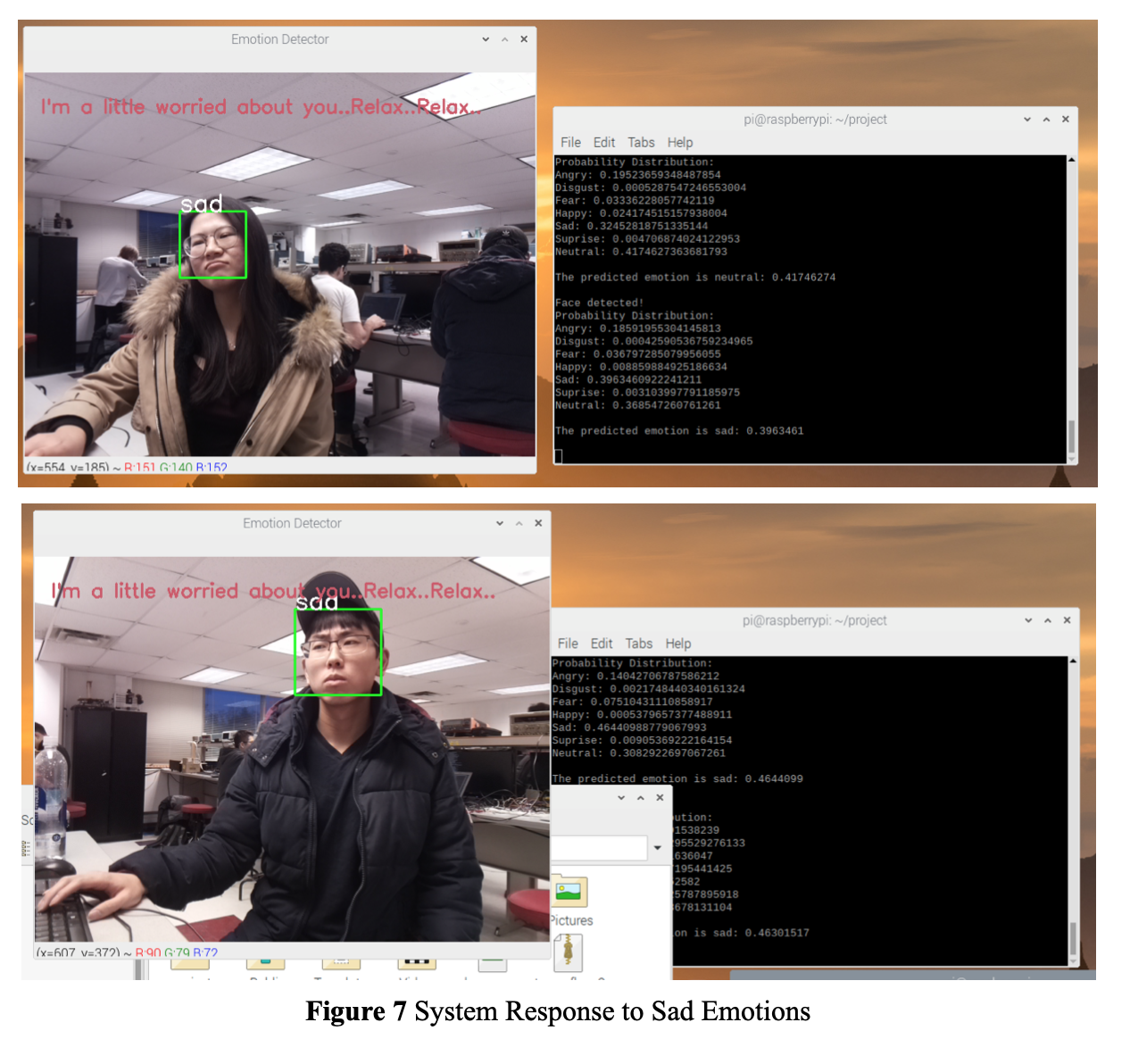
We designed the system to work in real-life conditions by considering the different circumstances. We set up an interval to check the emotion and play the corresponding music. This interval can be specified in the program and is implemented by a counter. For example, if the counter is set to 50, then for every 50 frames, the algorithm checks the predicted emotion and selects a good music. In other words, music will be played for every 50 frames. If there is no face detected at the checkpoint, music will not be played. In order to capture the facial expressions that can truly reflect a person’s emotion and mood, the algorithm requires three consecutive frames’ results. If the three frames yield the same predictions, the algorithm will consider the predict emotion is legal and a song is going to be selected; otherwise, the algorithm will not play any music until the next checkpoint. The probability distribution for the classification is printed in the console for log purpose and the predicted result is displayed on the upper left corner of the bounding box that indicates the position of the detected face. Once a song is selected and ready for playing, a message will appear on the window to imply this process. “A happy face a day keeps the doctor away” and “I'm a little worried about you..Relax..Relax..” are designed for happy and sad emotion response, respectively. We are glad Yvonne and Sam to help us demo the on-device performance. The following figures show how the system responded to the facial expression changes of Yvonne and Sam.

Issues
We had some issues when setting up environment and installing dependencies on raspberry Pi. We noticed that installing some packages could be problematic and should follow certain order to install in order to succeed. Installing OpenCV for python3 might fail due to missing dependency libhdf5_serial.so.103. We followed the reference 2 to figure out this problem. When installing keras, scipy was installed with keras together automatically. However, the installation of scipy could cause keras installation fail and our approach to fix this was to install the scipy and keras separately, i.e. installing scipy first. Since all we need to do on raspberry pi was to load the model, we used tensorflow-lite due to its specific design for on-device inference. We failed to build the tensorflow-lite repo provided by the official docs, instead, we pip installed the wheel file. The wheel files of various versions of tensorflow-lite can be found in the reference 3.
In addition, the computational power of raspberry Pi 3 is limited. Our first transfer learning model could be loaded on Pi 3 due to the memory limitation and the smaller transfer learning model sometimes could cause memory usage warning. Although the mini-Xception can run on the Pi 3, there was a latency between expression recognition and result printing. After switching to Pi 4, such latency disappeared and the inference time improved.
OpenCV may sometimes (rarely) raise -215 resize error when resizing a cropped face image. Based on our research, this error is not a result of bad implementation but an unresolved problem in openCV source code. To fix this, we used try and except to capture this error and ignore it.
Conclusion
One of the major conclusions we learned from the project is that it is difficult to choose proper models and deep learning algorithms which can be ran efficiently on the Raspberry Pi. In order to solve the problems such as inference time and model size, we have tried several different pre-trained bottleneck networks such as MobileNetV2 and VGG-16. We found that pre-trained model can save much time consumed on training process while self-trained model takes much more time on training and classification. Meanwhile, we have selected various expression databases with different number and size of images during the project. Although transfer learning provided a good result in training efficiency and accuracy, the time it takes to predict one frame is long. We utilized mini-Xception to improve the inference time and made it to work in a real-time level. After using mini-Xception, the accuracy and time efficiency is acceptable. Moreover, we switched from Raspberry Pi 3 model B to Raspberry Pi 4 to utilize its better computational power. It was valuable to improve the time efficiency of prediction.
Work Distribution

Project group picture

Sheng Li
sl3292@cornell.edu
Designed the overall software architecture, data preprocessing, and neural network implementation.

Xinran Li
xl792@cornell.edu
Implemented picamera and music selection algorthim, data preprocessing, and tested the overall system.
Parts List
- Raspberry Pi 4 upgrade -- $30.00
- Raspberry Pi Camera V2 -- $25.00
- Papercraft Building Kit -- $10.00
- Mini Portable Speaker -- $11.50
Total: $76.50
References
[1] Arriaga, Octavio, P. Plo ̈ger, and M. Valdenegro. Real-time Convolutional Neural Networks for Emotion and Gender Classification. arXiv e-prints arXiv:1710.07557v1, 2017.[2] Steps to Fix Dependency Missing When Installing OpenCV
[3] The Wheel Files for Installing Tensorflow-Lite
[4] Install OpenCV on the Raspberry Pi
[5] Install Keras on the Raspberry Pi
Code Appendix
// Emotion-xception.py
import os
import seaborn as sns
import matplotlib.pyplot as plt
from PIL import Image
import glob
import cv2
from sklearn.model_selection import train_test_split
import keras
from keras.callbacks import CSVLogger, ModelCheckpoint, EarlyStopping
from keras.callbacks import ReduceLROnPlateau
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
from FinalX5725.cnn import mini_XCEPTION
data = pd.read_csv('./FinalX5725/fer2013/fer2013.csv')
num_of_instances = len(data)
print("number of data:",num_of_instances)
pixels = data['pixels']
emotions = data['emotion']
usages = data['Usage']
num_classes = 7
x_train,y_train,x_test,y_test = [],[],[],[]
for emotion,img,usage in zip(emotions,pixels,usages):
emotion = keras.utils.to_categorical(emotion,num_classes)
val = img.split(" ")
pixels = np.array(val,'float32')
if(usage == 'Training'):
x_train.append(pixels)
y_train.append(emotion)
elif(usage == 'PublicTest'):
x_test.append(pixels)
y_test.append(emotion)
x_train = np.array(x_train)/255.0
y_train = np.array(y_train)
x_train = x_train.reshape(-1,48,48,1)
x_test = np.array(x_test)/255.0
y_test = np.array(y_test)
x_test = x_test.reshape(-1,48,48,1)
import matplotlib.pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
for i in range(4):
plt.subplot(221+i)
plt.gray()
plt.imshow(x_train[i].reshape([48,48]))
x_train.shape, x_test.shape
# hp
batch_size = 32
num_epochs = 100
input_shape = (48, 48, 1)
validation_split = 0.1
num_classes = 7
patience = 50
data_generator = ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=.1,
horizontal_flip=True)
model = mini_XCEPTION(input_shape, num_classes)
model.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
save_path = './FinalX5725/Weights/'
log_file_path = save_path + 'fer2013_emotion_training.log'
csv_logger = CSVLogger(log_file_path, append=False)
early_stop = EarlyStopping('val_loss', patience=patience)
reduce_lr = ReduceLROnPlateau('val_loss', factor=0.1,
patience=int(patience/4), verbose=1)
trained_models_path = save_path + 'fer2013_mini_XCEPTION'
model_names = trained_models_path + '.{epoch:02d}-{val_acc:.2f}.h5'
model_checkpoint = ModelCheckpoint(model_names, 'val_loss', verbose=1,
save_best_only=True)
callbacks = [model_checkpoint, csv_logger, early_stop, reduce_lr]
model.fit_generator(data_generator.flow(x_train, y_train,
batch_size),
steps_per_epoch=len(x_train) / batch_size,
epochs=num_epochs, verbose=1, callbacks=callbacks,
validation_data=(x_test,y_test))
// cameraxm.py
import cv2
import time
import numpy as np
import os
import cv2
from keras.models import load_model
from keras.preprocessing import image
from cnn import mini_XCEPTION
import random
import pygame
EMOTION_DICT = {0:'angry',1:'disgust',2:'fear',3:'happy', 4:'sad',5:'surprise',6:'neutral'}
model = load_model('./Weightsfer2013_mini_XCEPTION.85-0.64.h5')
face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml')
print("Model loaded successfully")
pygame.init()
required_size = model.input_shape[1:3]
last_emotion = -1 # neutral
last_last_emotion = -1 # neutral
happyTextCounter = 0
sadTextCounter = 0
def randmp3(emotion):
pygame.mixer.init()
if (emotion == 1):
random_music = random.choice(os.listdir("/home/pi/project/music/happy/"))
file = '/home/pi/project/music/happy/' + random_music
else:
random_music = random.choice(os.listdir("/home/pi/project/music/sad/"))
file = '/home/pi/project/music/sad/' + random_music
print("The music I would like to play for you is {}\n".format(random_music))
pygame.mixer.music.load(file)
pygame.mixer.music.play()
def make_prediction(frame, counter):
global last_emotion
global last_last_emotion
global happyTextCounter
global sadTextCounter
# convert image to gray scale
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect face in image, crop and resize
faces = face_cascade.detectMultiScale(gray_frame, 1.3, 5)
for (x,y,w,h) in faces:
face_clip = gray_frame[y:y+h, x:x+w]
print("Face detected!")
frame = cv2.rectangle(frame, (x,y), (x+w,y+h), (0, 255, 0), 2)
try: # -215 cv resize error
gray_frame = cv2.resize(face_clip, required_size)
except:
continue
gray_frame_img = image.img_to_array(gray_frame)
gray_frame_img = gray_frame_img.reshape(-1, gray_frame_img.shape[0], gray_frame_img.shape[1], 1)
gray_frame_img = gray_frame_img/255.0
pred = model.predict(gray_frame_img)
emotion_label = pred[0].argmax()
print("Probability Distribution:")
print("Angry: {}\nDisgust: {}\nFear: {}\nHappy: {}\nSad: {}\nSuprise: {}\nNeutral: {}\n".format(pred[0][0], pred[0][1], pred[0][2], pred[0][3], pred[0][4], pred[0][5], pred[0][6]))
print("The predicted emotion is "+str(EMOTION_DICT[emotion_label])+": "+str(max(pred[0]))+"\n")
cv2.putText(frame, EMOTION_DICT[emotion_label], (x,y), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 2)
# a successful detection requies three frams' results
if (counter % 30 == 0):
print("emotion: {}, last emotion: {}, last last emotion {}".format(emotion_label, last_emotion, last_last_emotion))
if (emotion_label == 3 and last_emotion == 1 and last_last_emotion == 1):
randmp3(1)
happyTextCounter = 15
elif ((emotion_label == 4 or emotion_label == 2 or emotion_label == 0) and last_emotion == 2 and last_last_emotion == 2):
randmp3(2)
sadTextCounter = 15
last_last_emotion = last_emotion
if (emotion_label == 3):
last_emotion = 1 # positive
elif (emotion_label == 4 or emotion_label == 2 or emotion_label == 0):
last_emotion = 2 # negative
else:
last_emotion = -1 # otherwise useless, set to neutral
if (happyTextCounter != 0):
cv2.putText(frame, 'A happy a day keeps the doctor away', (20,50), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (106,90,205), 2)
happyTextCounter -= 1
if (sadTextCounter != 0):
cv2.putText(frame, 'I\'m a little worried about you..Relax..Relax..', (20,50), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (106,90,205), 2)
sadTextCounter -= 1
cv2.imshow("Emotion Detector", frame)
videoCap = cv2.VideoCapture(0)
if (not videoCap.isOpened()):
print ("Error: No pi camera")
quit()
else:
print ("Camera is open")
counter = 0
while (True):
#print('The counter is ' + str(counter))
returnBool, frame = videoCap.read()
make_prediction(frame, counter)
k = cv2.waitKey(15)
if k == ord('q'):
break
counter = counter + 1
videoCap.release()
cv2.destroyAllWindows()