Voice-Enabled Espresso Maker
ECE 5725 Final Project - Scott Wu (ssw74), Charles Bai (cb674)
Overview

The goal of this project is to build a voice-controlled coffee machine "Aron" which is able to make coffee based on real time voice input. Our system is a 3D printed module that fits on top of the Nespresso Essenza Mini coffee machine. The Raspberry Pi listens for key words and phrases to actuate a servo accordingly to control the buttons on the coffee machine.
Hardware Design
Raspberry Pi & Circuits
We use a Raspberry Pi connected to a piTFT display touch screen. Raspberry Pi is perfect hardware system to run Snowboy hotword detection. Since we are using Raspberry Pi in command line mode, we use piTFT to display the command.


Coffee Machine & Add-on
The machine we are targeting is the Nespresso Essenza Mini. Although this is our ideal device, we would like our project to work on similar devices as well. We print an add-on holder that fits on top of the Espresso Maker that can press the buttons. This add-on fits snugly over the top of the machine with the foam pads. Velcro is attached to the top to secure the Pi.
Servo
We connect the servo to a bread board and connect Raspberry Pi to the bread board using a breakout cable to control the servo. The servo is glued to the bottom of the Add-on to press the buttons on the coffee machine.

Software Design
Overview
Our software is split into two stages: training and execution. In the training stage, we train our hotword through an online API, and also our phrase detection using frequency analysis and machine learning. We load the models we create in the execution stage. First the hotword detection is constantly listening. When a hotword is detected, the phrase detection starts to classify a command. Finally the command is sent to an actuation script to active the servo appropriately.

Hotword Training and Detection
We use Snowboy Hotword Detection from Kitt.ai to implement hotword detection. Snowboy offers two types of models: universal and personal models. Universal models require audio samples from hundreds of different people. For this reason, there only exists universal models for a few words, such as "Snowboy" and "Alexa". Personal models only require 3 audio samples, but are trained only for a single person. Using personal models we can train arbitrary phrases or words, but it will only recognize one person's voice.
Snowboy's Hotword Detection framework is useful because it provides a hotword detector comparable to that of Google or Microsoft, yet runs completely offline on a Raspberry Pi. However, since the software is proprietary, we are required to use their API to train the personal model. To train, we submit three 16 kHz, single channel, 16-bit signed PCM wave files, encoded in base64 to their training endpoint. The code for this can be found in "train-snowboy.py".
On execution, the python script opens up the microphone and sends the raw PCM data to the precompiled Snowboy binary. The sampling rate, number of channels and data format must match that which we used in training (Snowboy supports a couple other formats, but that is probably the more common one). A successful detection will trigger a asychronous call that writes the string "HOTWORD".
Phrase Training and Detection
We implement phrase detection with machine learning over the frequency bins of each phrase we wanted to detect. The coffee machine has two sizes of coffee, "espresso" and "large". Thus, we aimed to train on these two words, plus the word "cancel" to cancel the previous command.
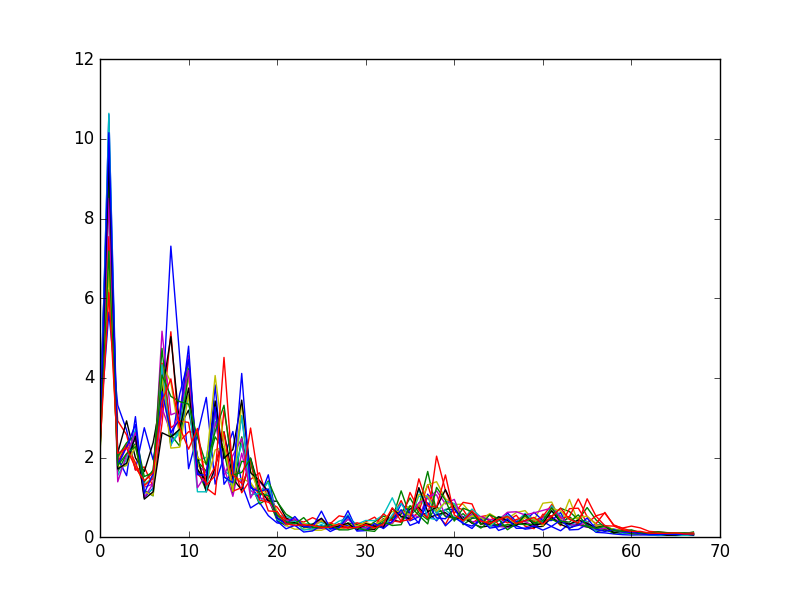
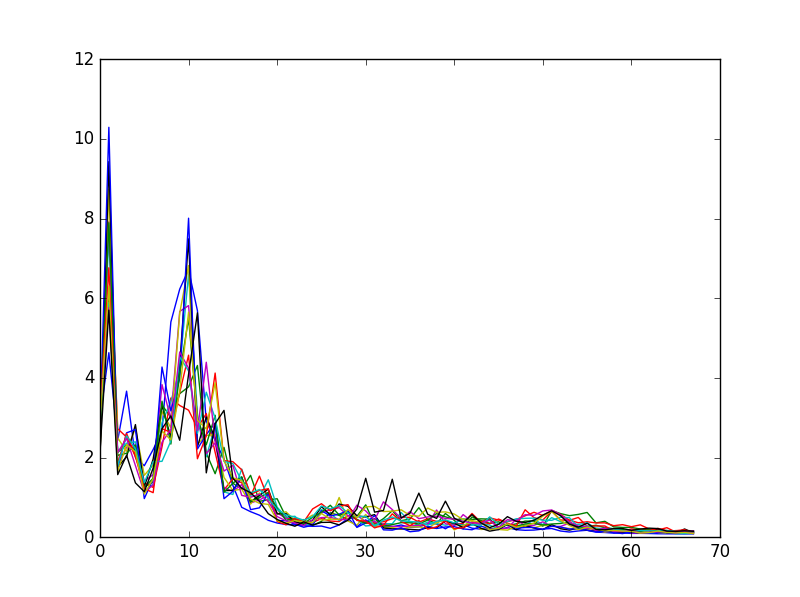
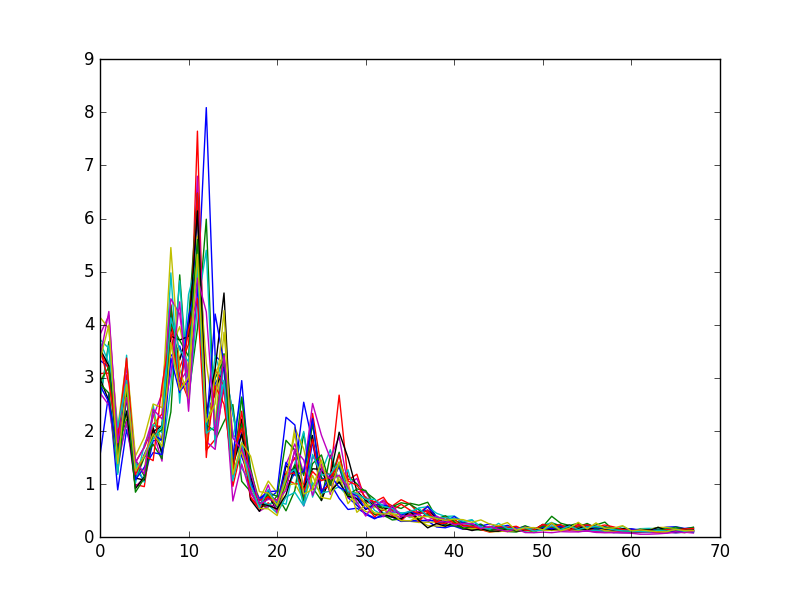
First, we record ourselves saying the word over and over again, with about 1 second of silence between each word. Our target output is 44.1 kHz, single channel PCM wave files. In the first training step, we parse the wave file and separates it into individual utterances, separated by the silences. Silences are based on a threshold and an amplitude. We run the FFT with a bin size of 1024 over individual utterances, crop out the human vocal range (100 Hz - 3000 Hz), normalize the values, and save these arrays for the training script.
In the training script, we read all the labelled arrays of individual utterance frequencies, and run a multi-class logistic classifier with SciPy. Using cross-validation techniques, we recorded an accuracy of 100% with 20-30 samples. In hindsight, these recordings were all done in a silent room, at the same volume, which might have made it poor training data for regular use. The classifier produced an object which we could serialize.
During execution, our python script first loads the classifier model we trained, and then waits for the input "HOTWORD". When triggered, we listen to the microphone until we hear an utterance and 0.5 seconds of silence, or up to 3 seconds total. We apply the FFT over this audio data using the same bin size and clipping parameters. The final array is fed into the classifier to produce a command. We output this command to the last part of our software.
Actuation
The servo is situated in between the two buttons. We hold the servo in one of three states: left, right and center. In the center, both buttons are unpressed. Left activates the espresso size coffee. Right activates large size coffee. The left and right buttons are held down for one second before returning to the center.
The servo is connected to a hardware PWM pin on the Pi. We use the RPi.GPIO library to control the angle and state of the servo. The actuation script waits for a command, either 0, 1 or 2, corresponding to the three commands we trained. After some error checking (e.g. we cannot cancel if the coffee is done), we translate these to PWM commands.
Communication
The hotword detection, phrase detection and actuation scripts communicate through FIFO queues. We have a script to setup and start the three programs in the background. This script executes on boot.
Gallery







Future Work
Single Microphone
For our prototype and demonstration, we used two micrphones for two reasons: sampling rate and sharing. Snowboy only allowed 16 kHz audio data, while our recognition ran at 44.1 kHz. The interface library, pyaudio, did not allow us to open the same audio device for two scripts.
We can resolve the sampling rate by resampling a higher rate down to 16 kHz. This would complicate the data collection a bit but would satisfy both sample rate requirements. Additionally, we can provide the audio data through yet another FIFO queue. This way both Snowboy and the phrase recognition script can share the same microphone.
Better Phrase Recognition
Our phrase recognition algorithms are nowhere near as good as commercial solutions, and could definitely be improved with more training data and better classifiers or models. This will improve the accuracy of our detections.
Add-On Weight
The servo proved to be strong enough to lift then entire add-on module while pressing the button. We could add a weight to the add-on so that it does not move while actuating.
Bill of Materials
| Part | Price |
|---|---|
| Raspberry Pi 3 Model B | $34.49 |
| Velcro Strips 3.5" x 0.75" | $2.48 |
| TowerPro SG90 Servos | $6.49 |
| USB Microphone Dongle | $4.35 |
| PS3 Eye (temporary) | $7.93 |
| 3D Printed Add-On | ~ |
| Foam | ~ |
| Glue | ~ |
| Total | $55.74 |
Contact Info

Scott Wu
ssw74
