Raspberry Pi Cluster
Accelerating TEA
By Jeff Witz and Jonathan Wu
Introduction
For our final project, we created an Raspberry Pi Encryption Cluster server, where we could send files from our laptops to be encrypted or decrypted with a certain key and number of rounds and automatically sent back. We wanted to accelerate the Tiny Encryption Algorithm (TEA) by exploiting parallel computation using three Raspberry Pi’s, ethernet cables, and a router. To this end, we used the OpenMP optimization pragmas and the MPICH library. We wanted to explore the different design spaces that the distributed computing environment offered us so we gathered performance data for the serial implementation, the OpenMP implementation, and the hybrid implementation (with both MPI and OpenMP) on a variety of file sizes and encryption rounds. With the hybrid implementation, we managed to achieve ~6x speedup from the serial implementation and ~2x speedup from the OpenMP implementation. In addition to speedup, our final result offered an interface which allows the user to send files to be encrypted or decrypted remotely. This was completed using TCP/IP socket programming in Python.
Testing & Design
High Level Overview
When it comes to parallel programming there are two programming models, symmetric multiprocessing (SMP) and asymmetric multiprocessing (ASMP). Symmetric multiprocessing is the model where physical memory is shared between the processors and there is no “master” process. In asymmetric multiprocessing, each processor is assigned to different tasks. The “master” processor is responsible for managing the execution of the program. This means that it has to split up data, send it out, and coordinate the computation of the other processors. When implementing these programming models, the OpenMP (Open Multi Processing) and MPICH (Multi Processing Interface) are the two of the most popular libraries. OpenMP is standard with “gcc,” and MPICH is a common implementation of MPI. There are alternatives such as OpenMPI, however, we chose MPICH because we found a lot of documentation on this library. We were also able to learn a lot about the implementation of these technologies from this paper.
OpenMP is a library for shared memory multi-processing. It is very easy to import because it is included with most systems with “gcc.” Because it supports shared memory multi-processing, we used this for our symmetric multiprocessing model. We used the MPI to implement our asymmetric multiprocessing programming model.
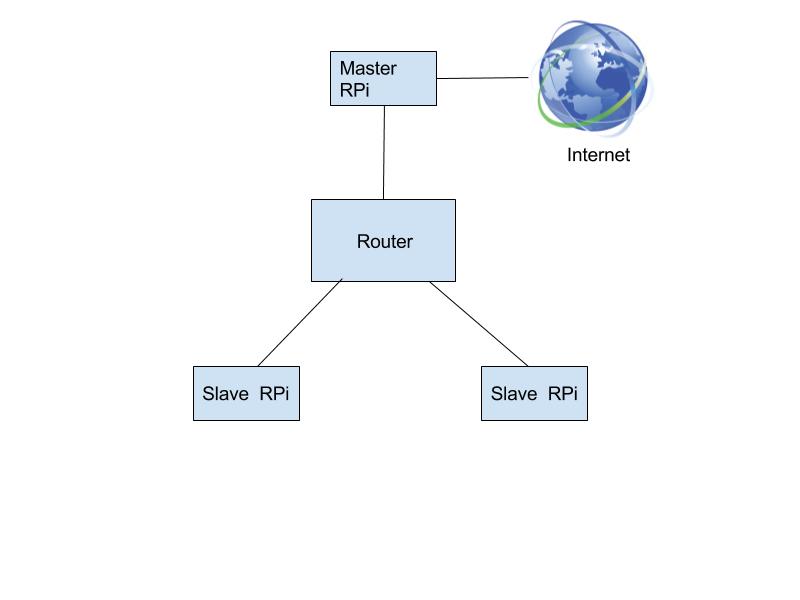
Beowulf Cluster Configuration
Cluster Configuration
In order to use MPI to communicate from the master node to the slave nodes, we had to authorize RSA keys to allow the master node to ssh into the slave nodes without requiring a password. We changed the slave nodes hostnames to ‘node1’ and ‘node2’ by changing the existing hostname in ‘/etc/hostname’. We ran the command ‘ssh-keygen -t rsa’ on the master node to generate a ssh key for the slave nodes. We then added the public rsa key to the slave nodes’ authorized keys by running ‘cat ~/.ssh/id_rsa.pub | ssh pi@(slave node’s IP address) “cat >> .ssh/authorized_keys”’. After adding the public key to the slave nodes we created ssh keys on the slave nodes and concatenated their respective public RSA keys to the master node’s authorized keys.
To connect the system together for MPI, we used a router and ethernet cables. Each Raspberry Pi was connected to this router via ethernet. We logged the IP addresses assigned to each Raspberry Pi and added it to a file which allows MPI to communicate to these hosts. We placed the master Pi’s IP address as the first and the other Pis in subsequent lines. This denoted the rank for each Pi and allowed us to keep track of which thread was the master thread when programming.
We use OpenMP on the Raspberry Pi level and MPI on the Raspberry Pi network level. On each Raspberry Pi, OpenMP is used to parallelize the computation across the four cores present in the processor. As previously stated, this is performed using shared memory. We also split up the data into thirds so each Raspberry Pi gets an equal portion of the data to run encryption on. The data is moved using MPICH library commands. The data is then recollected and compiled on the master Raspberry Pi, which sends the encrypted file back to the user which sent it.
Serial Implementation
The first step in generating our design was to create a working serial implementation of the Tiny Encryption Algorithm. This algorithm was chosen because of its simplicity and relative ease to implement. This algorithm is a symmetric block cipher, meaning it is divided into “blocks” and uses the same key to encrypt and decrypt. The algorithm generally uses blocks of 64 bits. It also uses a key of 128 bits. It comprises of a series of XOR’s, additions, and shifts. In our implementation, the function takes two 32 bit integers and outputs two 32 bit integers which contain the encrypted or decrypted text.
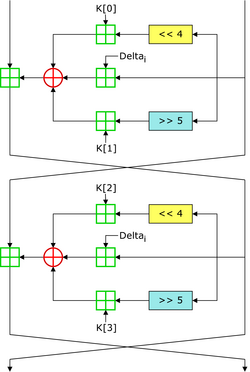
Tiny Encryption Algorithm Diagram from Wikipedia
To test our serial implementation, we first filled an array of 32 bit integers with N numbers. This would be of size N*4 bytes. Two 32 bit numbers would correspond to one block. We would then feed this into the encryption/decryption function one block at a time. This process would be repeated until all of the blocks in the original plaintext were encrypted. We would then decrypt this data and compare it to the original to ensure that they were the same. Once we were certain that the algorithm was encrypting and decrypting properly, we moved towards using OpenMP to parallelize the computation across the four cores in the Raspberry Pi.
OpenMP Implementation
The next step was to parallelize the computation across the four cores in an individual Raspberry Pi. To do this, we used OpenMP pragmas. OpenMPI libraries are generally included with “gcc”, so they are fairly easy to include. We just had to include the “omp.h” header and write “-fopenmp” when compiling with “gcc.”
We had to restructure our code slightly to accommodate the OpenMP directives. We created a wrapper function entitled “mpEncrypt” which calls the “encrypt” function however many times it needs to to encrypt all of the blocks in the file. We placed a OpenMP pragma outside the for loop in “mpEncrypt”. This can be seen here:
“#pragma omp parallel for default(shared) private(i) schedule(dynamic, chunk) num_threads(4)”
This tells the OpenMP how we wish to parallelize the loop. This line identifies it as a “for” loop. The lines “default(shared) private(i)” sets the all of the variables besides the loop index to shared. “schedule(dynamic, chunk)” tells it to schedule the threads dynamically (as opposed to statically assigning blocks before execution). “Chunk” is a previously defined number which tells the compiler how many blocks to assign each thread. This was generally set to 1 or 4. Finally, we set the number of threads to 4, one for each processor.
OpenMP Visualization
For the most part, implementing OpenMP was fairly straightforward. We briefly had issues getting the pragma working and getting speed up, but we found that this was because we were not including the “-fopenmp” flag while compiling. Once we had this working, we saw a roughly 4x speedup compared to the serial version. This was exactly what we expected.
MPICH Implementation
To allow the Raspberry Pi’s to communicate and send data to each other through the ethernet router, we used the MPICH library. This is an implementation of the MPI standard. We chose this library because it was used in a tutorial which was very helpful in getting MPI working. MPI works by running the program on each of the Raspberry Pi’s. Each Raspberry Pi can be identified by its assigned rank. We used the Raspberry Pi at rank 0 as the master. This meant that is was responsible for receiving the file, splitting it up, collecting it, and sending the encrypted file back to the client which asked for it.
The master Raspberry Pi would split up the file into thirds. If the file was not divisible, then padding would be added. We then use “MPI_Bcast” to send some important data, such as the key and text size, to each of the processors. We used a broadcast in this scenario because we want each processor to receive the exact same data. We would not use this to send out the data to be encrypted because each processor should receive a different third of the data. There are two ways to send out data to be encrypted using OpenMPI. The first is to use the “scatter” and “gather” methods to send out the data and then collect the results in on the master Raspberry Pi. The alternative way is to use carefully organized “send” and “receive” methods to manually split up the data and collect it on the main Raspberry Pi. Although we initially used the “scatter” and “gather” method, our final implementation used the “send” and “receive” methods. This was because we believed that the “scatter” and “gather” methods could have been causing some issues that we were having where the algorithm was not offering the speedup that we desired. This was not the root cause, but we ended up keeping it because it did work at roughly the same speed as the “scatter” and “gather.” After all of the data was sent out, each Raspberry Pi would encrypt or decrypt the data provided, depending on the mode that it was set to by the user. We also added a feature which allows the user to run the encryption for a specified number of rounds. This is done to increase the security of encryption. Once the encryption was complete, the data was sent back to the master Raspberry Pi to be compiled and output. Throughout this process, we used MPI “barriers” to ensure that the threads are synchronized where they need to be.
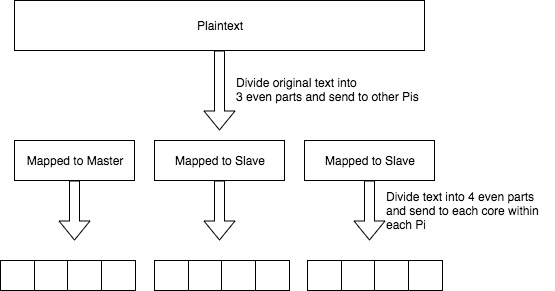
MPI and OpenMP Hybrid Visualization
The initial version of this code compiled and encrypted the text properly. However, we found that it did not offer the speedup that we expected. We found that the OpenMP version on a single Raspberry Pi was faster, which should not have been the case. After some investigating, we found that it was because the algorithm was too fast. This meant that the delay of communicating the data through the system (100 Mbps at its fastest) using MPI would be too expensive compared to the computation. To fix this, we added the feature of performing multiple rounds of encryption. This makes the computation more expensive, and it also makes the encrypted file more secure. Adding an increasing number of rounds allowed us to see more speedup using the MPI implementation. Afterwards, we found that the speedup was faster than it should be. The MPI implementation was 16x faster than the standard. However, this should not be possible because we only have 12x parallelism. It turned out this was due to the fact that MPICH automatically adds compiler optimizations (-O2) to the program that were not used while compiling the OpenMP and serial programs, giving the MPI version an unfair advantage. After adding this flag to the OpenMP program for fair comparison, we found that the highest speedup was roughly 6x, which makes much more sense.
Python Interface
In order to have the Raspberry Pi cluster encrypt/decrypt files from a user’s computer, we used socket programming in Python. We created a host python script that would wait for a client to connect.
Host Startup Console
Once the client established a connection, the client’s first message would denote whether they wanted encryption or decryption, the number of rounds to perform encryption/decryption, a 16 byte alphanumeric key, and a path to the file they want to encrypt or decrypt.
Example Input for Client Python Script
The host side would parse the message and prepare for a file transfer. Before the client starts to transmit the file, it will send over another message that denotes the filename and size for the following transfer. The host side will parse the message and get ready for the file transfer and create a new file to hold that transferred file’s data. It will enter a while loop that will check if the entire file has been received. If it has not, the host will call receive and concatenate the read buffer to created file and decrement the file size by the read buffer’s size. Once the file size hits zero, the host will exit the while loop and perform the desired process on the file by using the “os” module to issue command line calls. While the host is performing the process, the client shuts down the socket and goes into receive mode because it finished sending packets of data. The client side will wait until it receives a specific packet from the host side.
Client Console Output After Encryption
When the host finishes processing the client’s file, it will notify the client that an impending file transfer is about to happen. This will move the client out of the wait and prepare it for the file transfer. The host sends over the filename and size of the transfer to the client. The client will enter a while loop that checks whether the file size is zero, otherwise it will keep calling receive and appending the read buffers to a new file. Once the file has been received, the host and client both close the connection. The host goes back to waiting for another connection to handle.
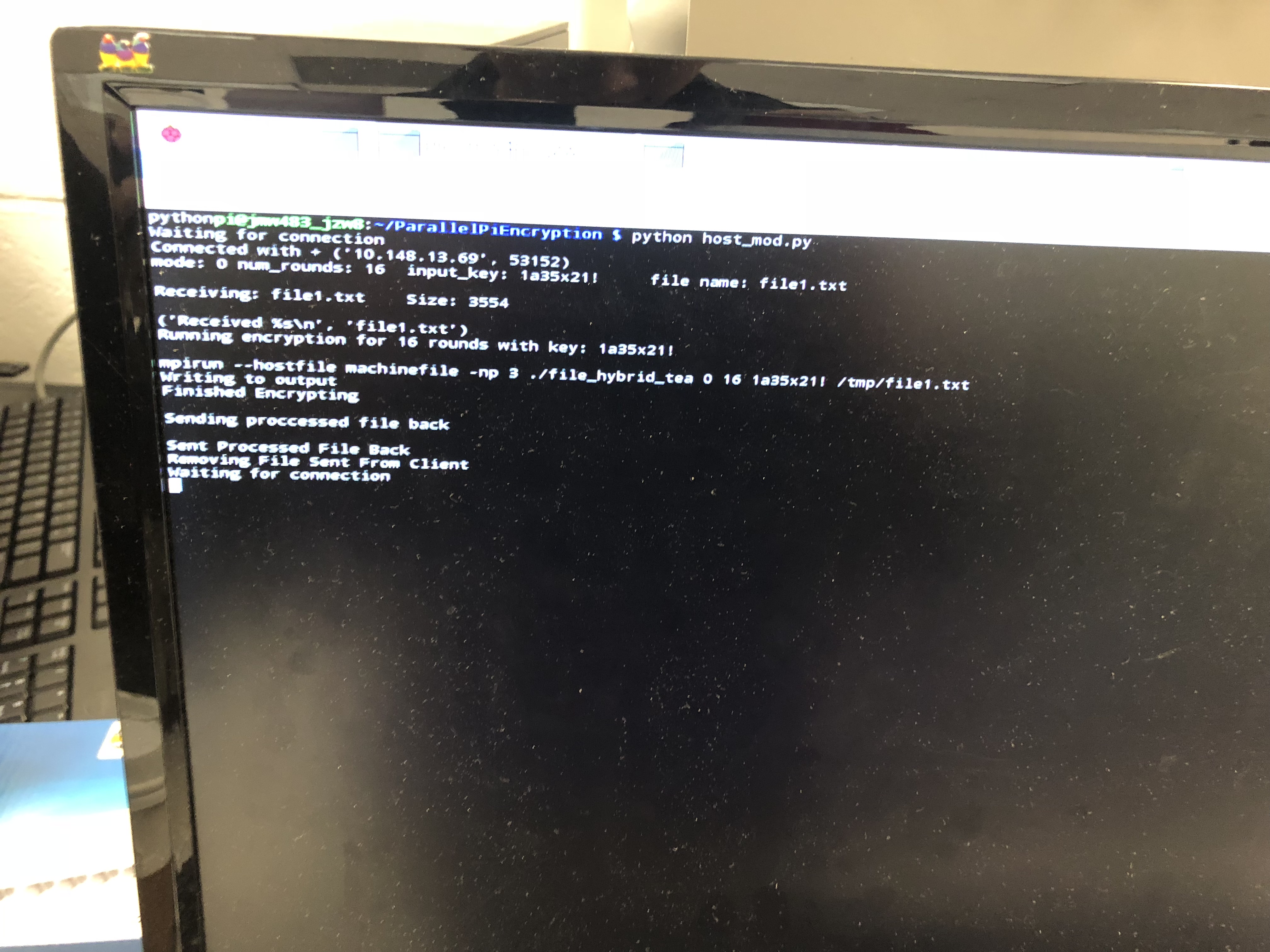
Host Console Output After Encryption
Testing
We had two primary versions of the files for this project. One version was used for testing the timing and functionality of our implementation to ensure that we were getting speedup. To perform timing, we used the timing functions provided by the OpenMP and MPI libraries. First, the plaintext would be filled. Then, we would start the timer and begin encryption. Once encryption was complete, we would stop the timer. This would be printed so we have the time for encryption. We would then decrypt the text and compare it to the original. We created a verify function that would check whether the encrypted and decrypted plaintext would match the original plaintext. Once we verified the plaintext, we were sure that the timing figures were accurate and we could include them for comparison. We ran this process for the serial, OpenMP, and MPI versions so we would be able to compare their runtimes.
The second version was the encryption server used to encrypt and decrypt data. As previously described, this allows the user to send a file via TCP/IP and received an encrypted or decrypted file automatically. To test this, we would generate a text file to encrypt. We would then send the file to the cluster using Python scripts. The cluster master would then perform the encryption or decryption and then send the file back. This final version used the optimized MPI model. We did not time this version because we were focused on the functionality of this model as opposed to efficiency in the previous model. To verify it, we would create a text file and send it to be encrypted. Once we received the encrypted file, we would send it back to be decrypted with the same key. If the texts matched, then we knew that the algorithm worked.
We interfaced the C code with the python code by using the OS module to run the generated binary. We tested to see if the python code was working by sending files over from our laptops using the corresponding client python code.
Example File Before Encryption
Example File After Encryption
We sent over files to be encrypted and checked the output file to see if it matched the input file. We then sent the same encrypted file for decryption to check if it were the same as the input file.
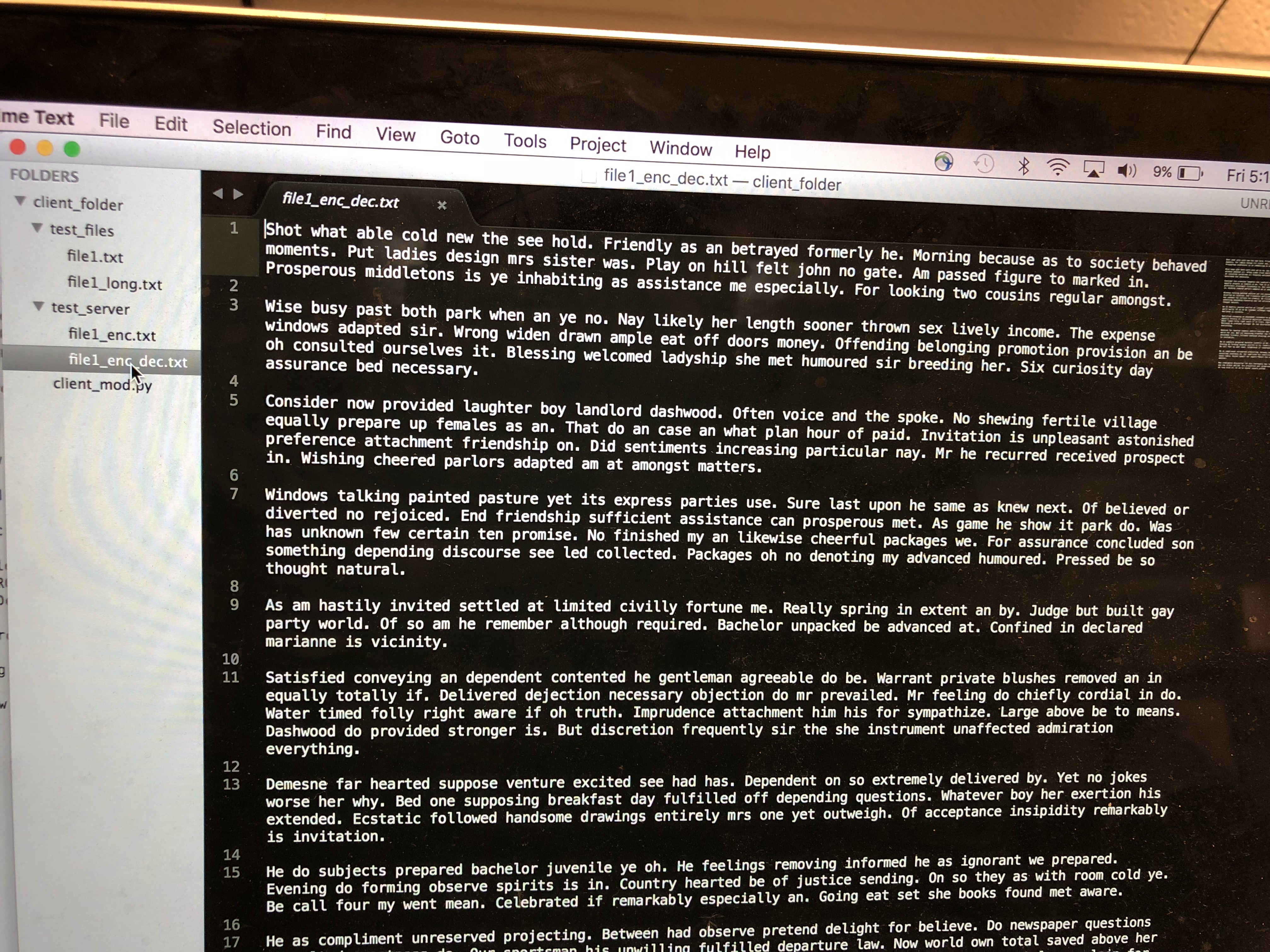
Example File After Encryption and Decryption
Results
These tables show the execution time for various configurations. The primary variables we explored were the file size and the number of rounds. We tested each configuration (standard, OpenMP, and hybrid) using rounds ranging from 1 to 32 and file sizes of 240 kB to 240 MB. In general, these tables reveal that the hybrid configuration worked best for a higher number of rounds with larger files. The OpenMP configuration worked best in most other cases. The graph shows the speed up compared to the standard version. The y axis was calculated by diving the runtime of the improved version by the runtime of the serial version for the corresponding file size.
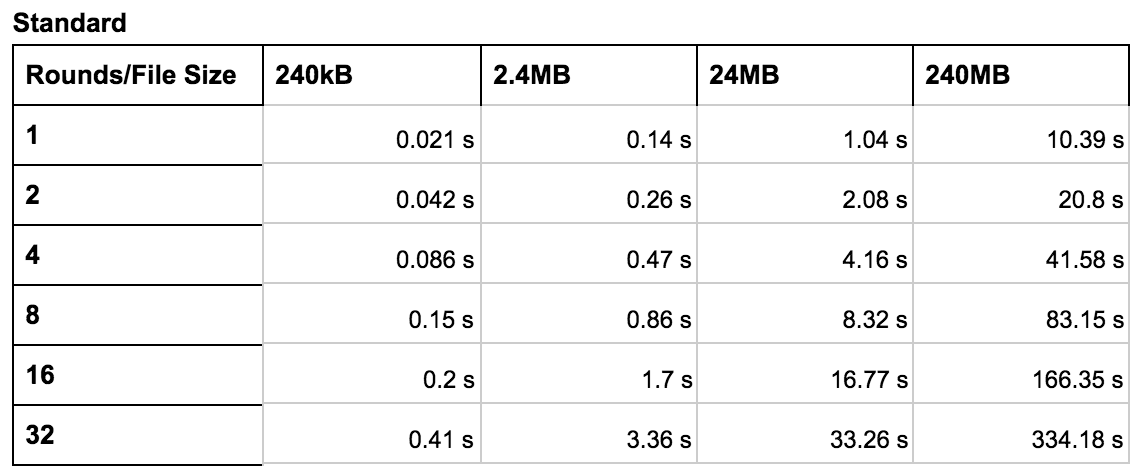
Serial Encryption Runtime
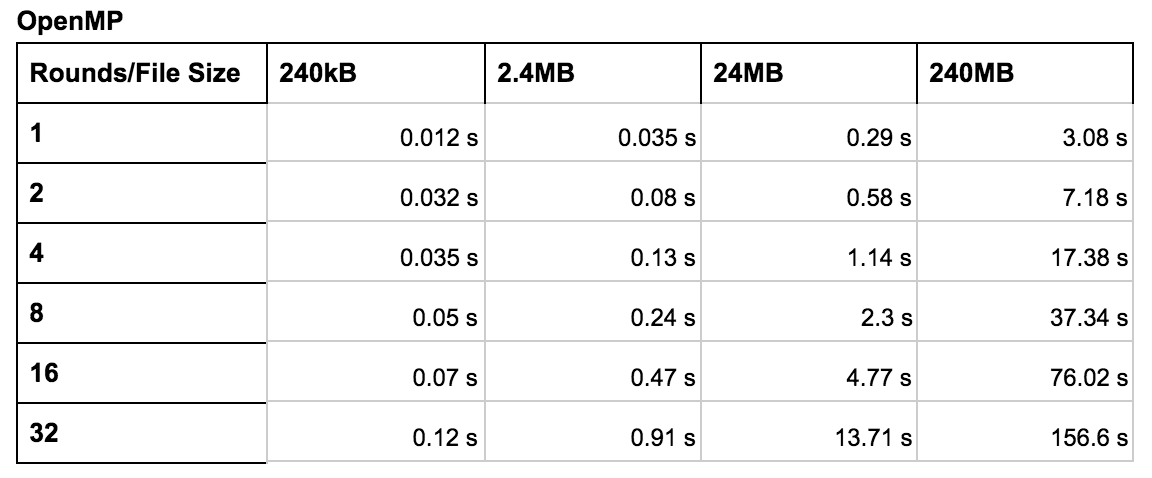
OpenMP Encryption Runtime
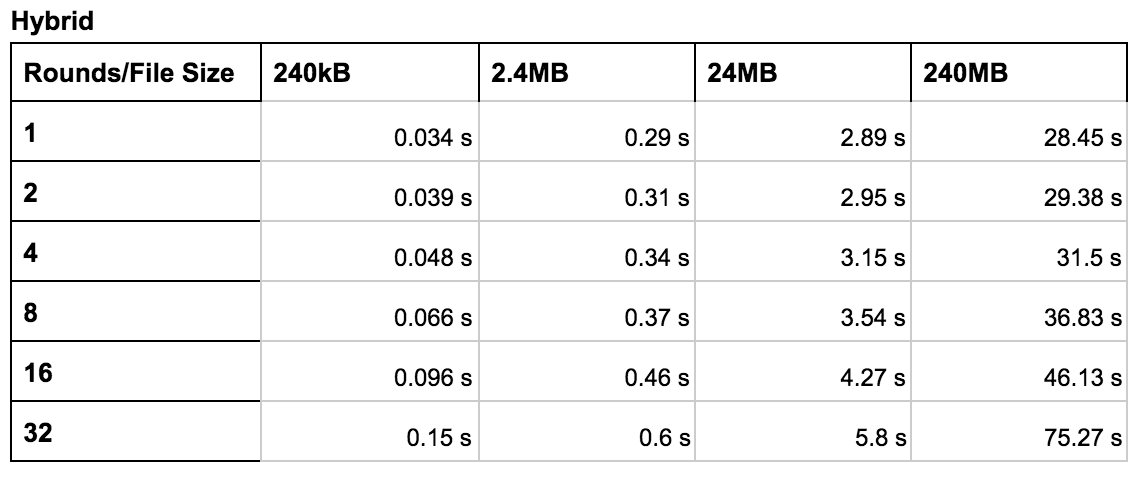
OpenMP & MPI Hybrid Encryption Runtime
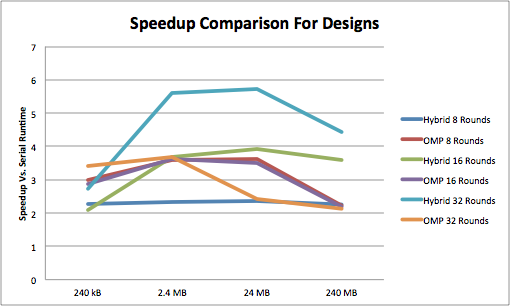
Speedup Comparisons
Conclusion
Overall, we were successful in the goal of our project in achieving a speedup using a hybrid of OpenMP and MPI. Our final hybrid version delivered a 6x speedup over the standard version and a 2x speedup over the OpenMP version using 32 rounds and a 240 MB file. However, one of the most important conclusions based off the data that we collected is that it is not always the case that parallelizing a computation improves performance. For the computations under 8 rounds and with smaller files, the OpenMP version of the code was faster than the hybrid version. This was due to the fact that there was a large amount of overhead associated with transmitting files. The router can only transmit at, at most, 100 Mbps. When there is a lower amount of computation (i.e. less rounds and smaller file sizes), then the communication latency is higher than the computation latency. This means that we cannot achieve much of a speedup. However, when increasing the computation to account for this, we do see a speedup. The speedup comparison graph displays this. As we can see, the 32 round hybrid offers the highest speedup when compared to the standard implementation. The 16 round hybrid also does well, but only for larger file sizes. As the number of rounds go down, the hybrid version performs worse due to the previously mentioned reasons.
In conclusion, we found that the using a hybrid OpenMP and MPI approach to parallelizable computations is a very reasonable way to improve the performance of certain algorithms. In this case, we saw improvement with the Tiny Encryption Algorithm. However, when using these methods, it is important to consider the cost of computation vs. the cost of communication. One round TEA cannot benefit from this setup. However, multiple round of TEA or more complicated algorithms may see the benefit of this system.
Future Work

One additional feature that would be interesting to add would be to support different encryption algorithms such as AES. As previously stated, the issues we came across with MPI were due to the fact that TEA is too fast compared to the communication latency. This may be less of an issue with more complex algorithms such as AES. Additionally, it would be interesting to implement public key encryptions algorithms such RSA. We could also feasibly expand our platform to other algorithms besides encryption, such as N-Body simulations. We would also be interested in integrating more Raspberry Pi’s into the system and seeing its effect on the amount of speedup that we can achieve. On the server side, we could expand it to include multithreading so that it is capable of receiving multiple files at the same time, as well as sending them back.
Team Contributions
Jeff
Jeff primarily worked on constructing the algorithm and interfacing it with the OpenMP and OpenMPI libraries. This primarily involved writing the algorithm code, figuring out how to use OpenMP pragmas to parallelize it, as well as using OpenMPI commands to manage data movement. He also worked on creating verification and debugging code.
Jonathan
Jonathan primiarliy worked on configuring the cluster so that the Raspberry Pis could communicate with each other. Jonathan also wrote the code for the host and client in order to facilitate file transfers through server sockets. He also helped with debugging the MPI and OpenMP code.
Appendix
Code
Code can be found on our GitHub Repo. All the finalized code is located in the directory 'FinalCode' and there is a readme within that directory detailing how to run the code.
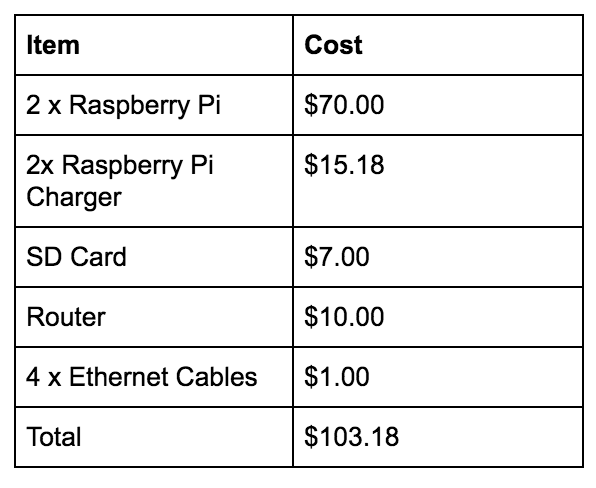
Project Costs